Results of Benchmark
Setup
EC2 m5.4xlarge
| Key | Value |
|---|---|
| vCPUs | 16 |
| Memory (GiB) | 64.0 |
| Memory per vCPU (GiB) | 4.0 |
| Physical Processor | Intel Xeon Platinum 8175 |
| Clock Speed (GHz) | 3.1 |
| CPU Architecture | x86_64 |
| Disk space | 256 Gb |
Details about the instance type
Datasets
All the information provided for a default seed 42. Size on disk is a total size of compressed parquet files. An amount of rows depends of SEED that was used for generation of the data because an amount of transactions for each id (customer id) per day is sampled from binomial distribution.
See src/lib.rs for details of the implementation.
Tiny Dataset
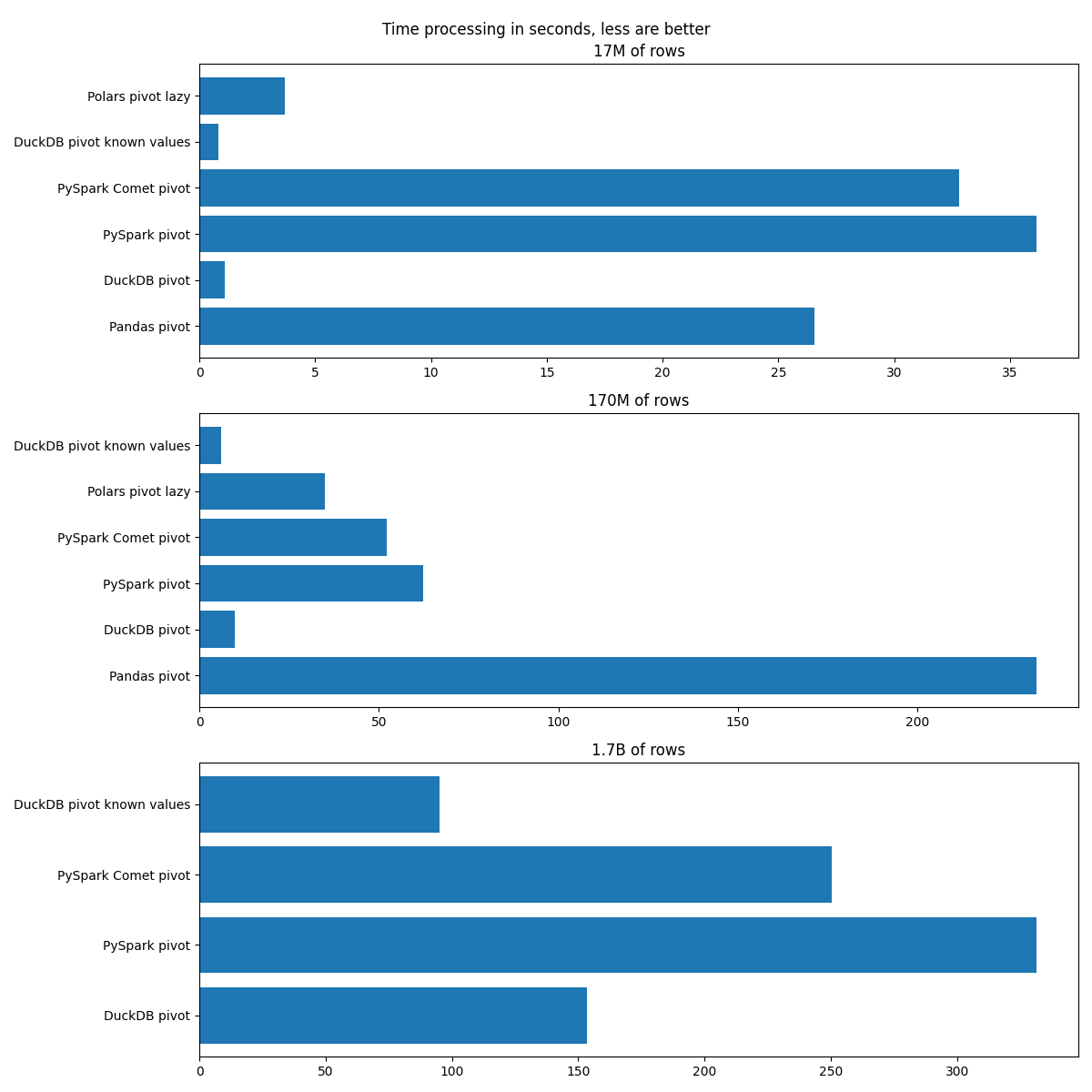
Amount of rows: 17,299,455
Size on disk: 178 Mb
Unique IDs: 1,000
| Tool | Time of processing in seconds |
|---|---|
| Pandas pivot | 26.55 |
| DuckDB pivot | 1.10 |
| PySpark pivot | 36.14 |
| PySpark Comet pivot | 32.80 |
| DuckDB pivot known values | 0.81 |
| Polars pivot lazy | 3.68 |
Small Dataset
Amount of rows: 172,925,732
Size on disk: 1.8 Gb
Unique IDs: 10,000
| Tool | Time of processing in seconds |
|---|---|
| Pandas pivot | 233.18 |
| DuckDB pivot | 9.87 |
| PySpark pivot | 62.25 |
| PySpark Comet pivot | 52.20 |
| Polars pivot lazy | 35.06 |
| DuckDB pivot known values | 6.03 |
Medium Dataset
Amount of rows: 1,717,414,863
Size on disk: 18 Gb
Unique IDs: 100,000
| Tool | Time of processing in seconds |
|---|---|
| DuckDB pivot | 153.57 |
| PySpark pivot | 331.40 |
| PySpark Comet pivot | 250.47 |
| DuckDB pivot known values | 95.07 |