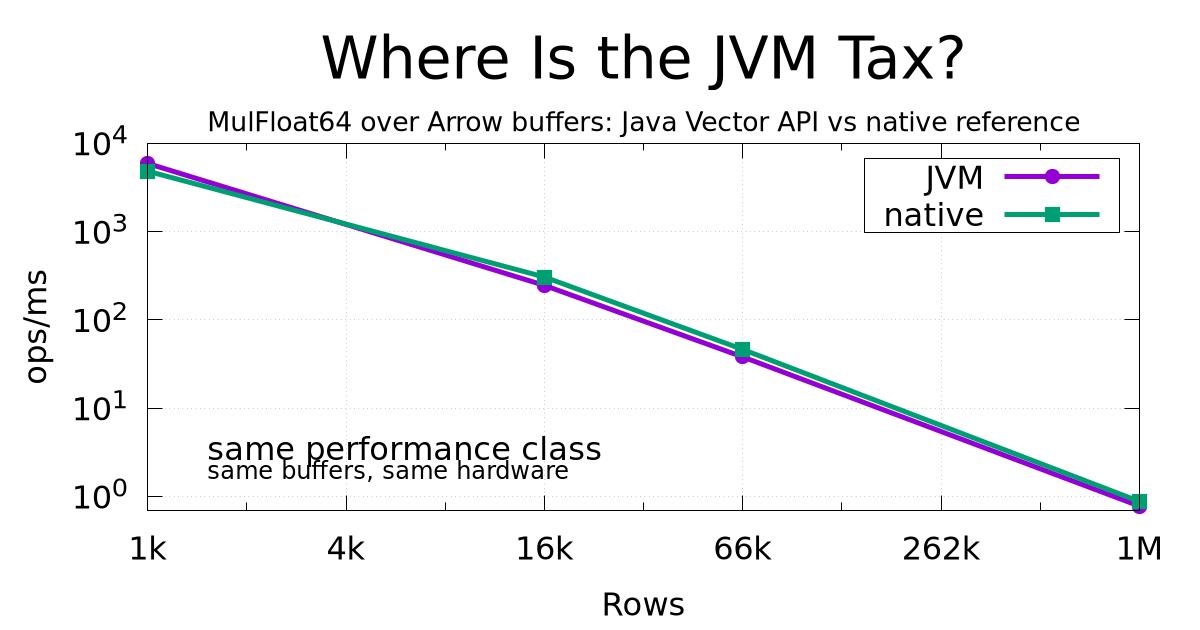
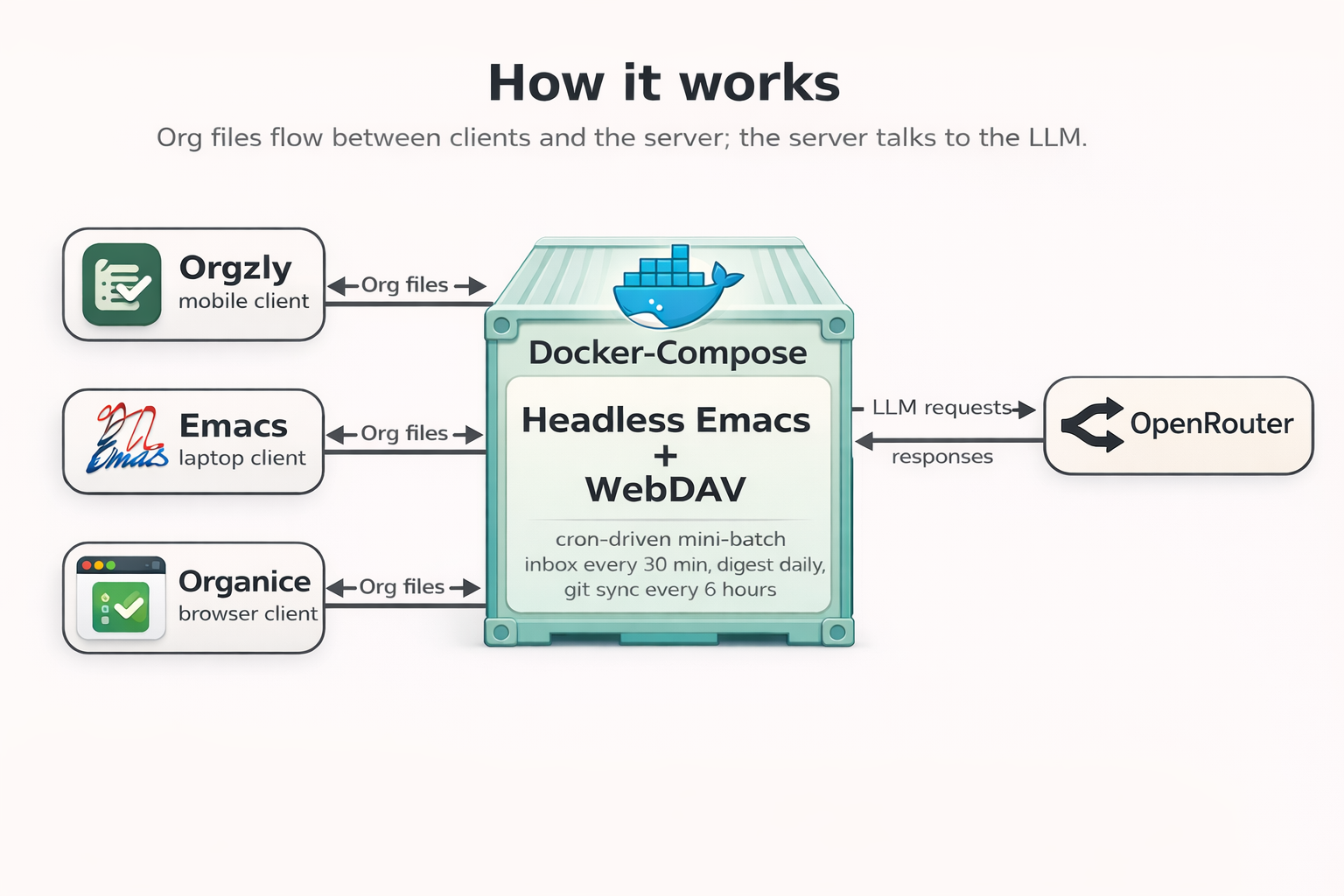
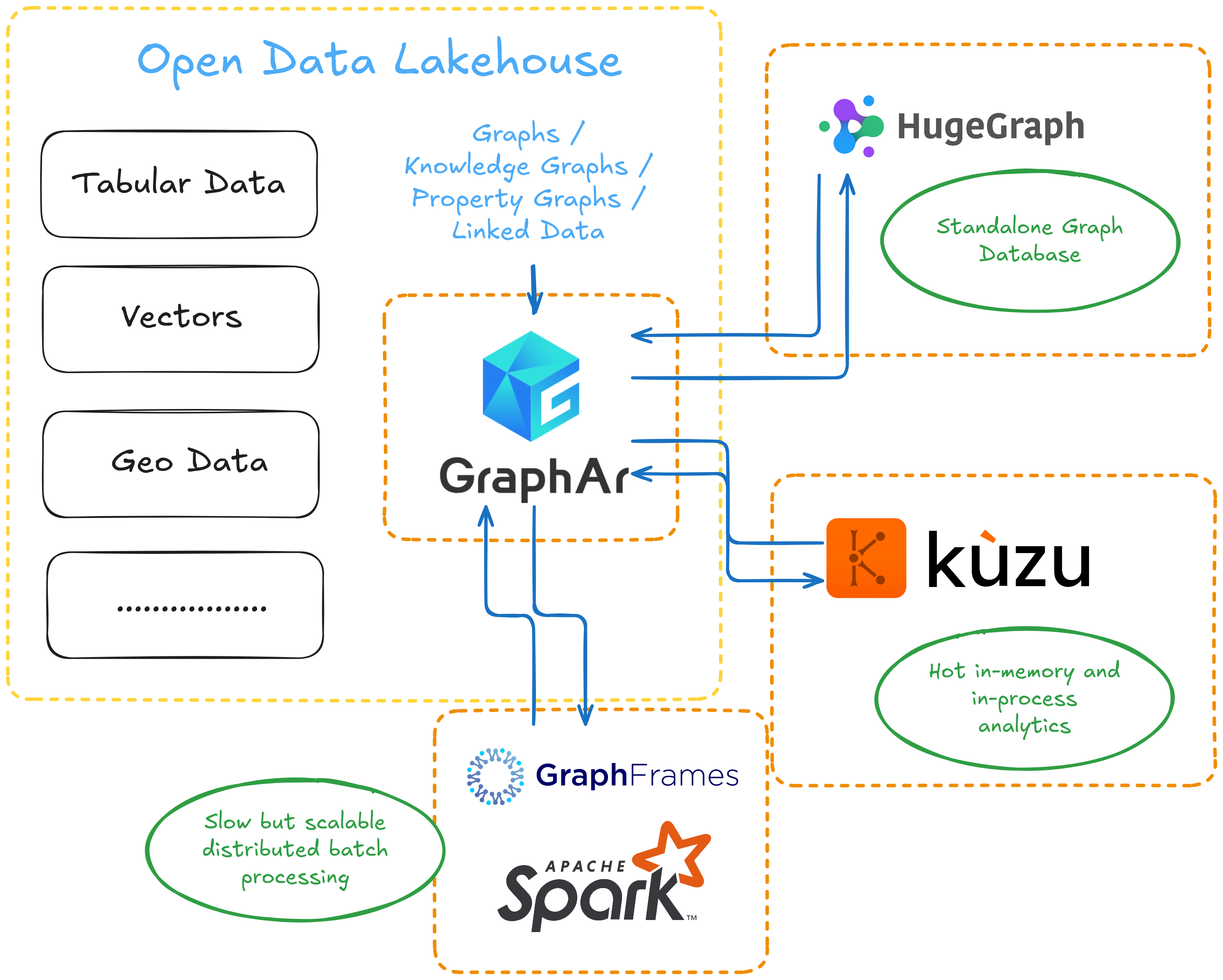
Yes, I really ended up running headless Emacs in Docker Compose. Yes, it actually works. And yes, in this blog post I will explain why I think this setup makes much more sense than it sounds. I will start with the format question and why Org Mode still looks like the strongest plain-text foundation for combining notes, TODOs, scheduling, digests, and second-brain workflows. Then, I will explain why Emacs was chosen not just as an editor, but as the backend runtime for reliable Org processing and as the orchestrator for LLM-based automation. Finally, I will describe the two roles AI plays here. It is part of the system itself, but only inside carefully bounded workflows, and it is also the reason I could realistically build this kind of strange personal infrastructure in the first place. This project is not a product, not a SaaS, and not a generic framework. It is software for one user, built around one user’s workflows, from open-source pieces like Org Mode, gptel, and Elfeed. What changed in the AI era is that this kind of narrow, deeply personal software became much more realistic to build.