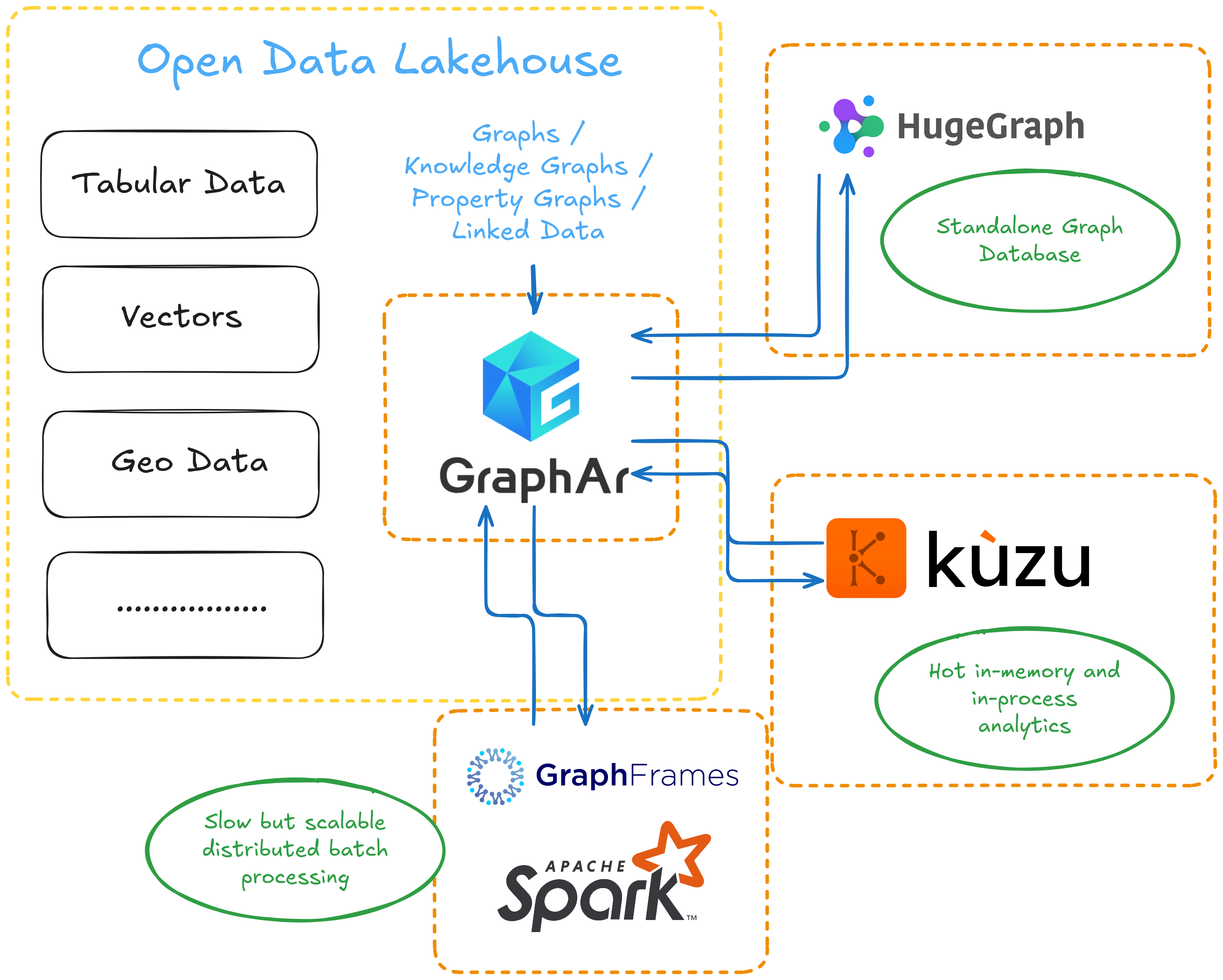
Graphs, Algorithms, and My First Impression of DataFusion
I don’t think anyone besides me has considered using Apache DataFusion to write graph algorithms. I still don’t fully understand DataFusion’s place in the world of graphs, but I’d like to share my initial experience with it. Spoiler alert: It’s surprisingly good! In this post, I will explain the weakly connected components problem and its close relationship to the common problem of modern data warehouses (DWHs), namely, identity resolution. I will also describe an algorithm for connected components in a MapReduce paradigm. I consider this to be the algorithm that strikes the best balance between performance and simplicity. Finally, I’ll present my DataFusion-based implementation of the algorithm and the results of toy benchmarks on a graph containing four million nodes and 129 million edges. As always, keep in mind that this post is very opinionated!