TLDR;
I do not think maintaining legacy OSS is romantic. Most of the time it is boring, slow, and constrained by things you did not design and cannot simply throw away. That was exactly the situation with GraphFrames, a 10-year-old project with a lot of history and not enough active maintenance. Before I could do feature work seriously, I first had to make the project function as a project again: fix the build, redesign publishing, re-check old issues, improve tests, and clean old code without breaking a library that had already been integrated into important long-running workflows.
I was doing this neither for money nor because I wanted to promote anything. I was doing it because I still believe, in a fairly direct GNU Manifesto sense, that software which is useful to other people is worth maintaining even when no company is paying for it. This sounds naive only if one has already accepted that all serious engineering must be attached to a business model. I do not accept that. In practice, the work was a constant struggle between interesting engineering and necessary engineering. New algorithms, Graph ML tooling, Spark Connect support, performance improvements, this was the rewarding part. Releases, benchmarks, publishing, CI, compatibility, issue triage, this was the part without which the rest was meaningless. Still, I am proud of what was achieved: depending on the workload, GraphFrames became roughly 3x to 30x faster, the issue backlog dropped from more than 300 to around 30, the library was adapted to modern Spark concepts such as Connect and AQE, it gained proper Graph Machine Learning tooling and multiple new algorithms, and the project now has a rebuilt website, regular automated releases, and nightly builds in Central Snapshots.
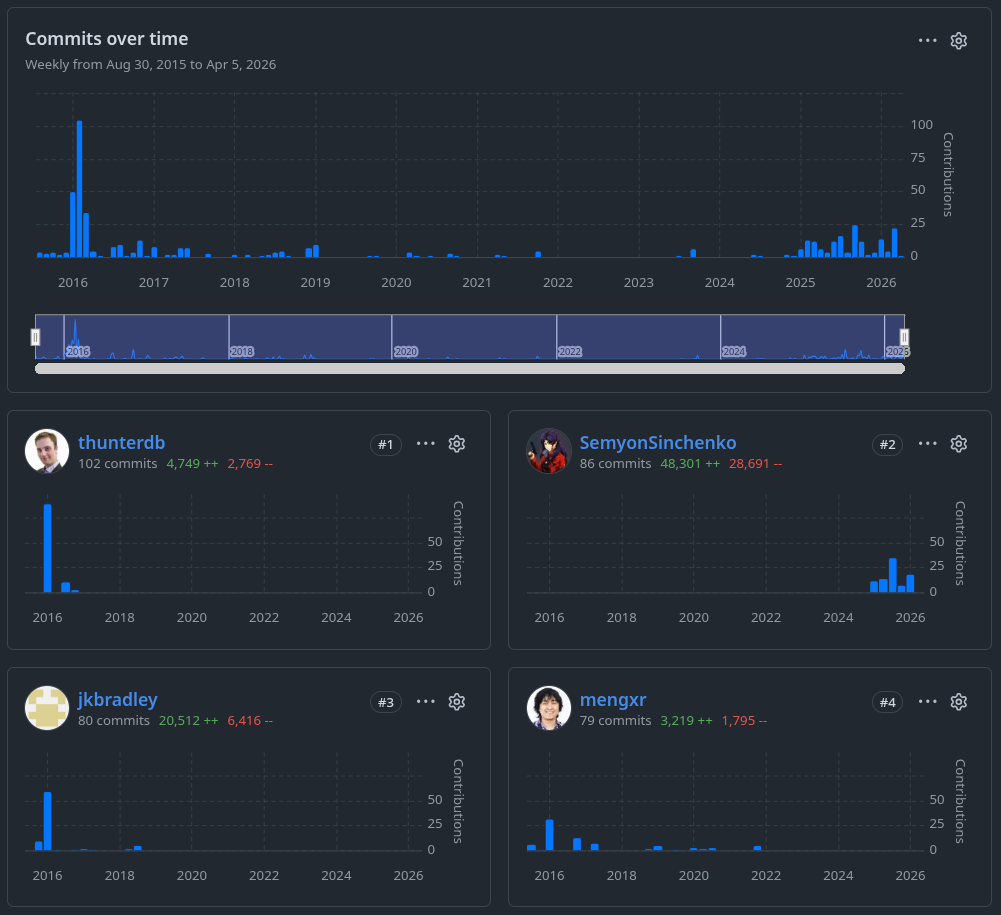
The repository history does not tell the whole story, of course, but it shows one important part of it quite well: GraphFrames had a strong early phase, then a long period of inertia, and only much later something that could honestly be called a revival.
The people who made it possible
I do not want to present this story as if I revived GraphFrames alone. That would be false.
Russell Jurney effectively took on the administrative and organizational side of the revival. He got the graphframes.io domain, commissioned a new logo, kept emailing and pushing former maintainers until we got the necessary access, wrote blog posts, and generally did the unglamorous but critical work of making the project visible and operational again. This kind of contribution is easy to underestimate if one looks only at commits. I do not underestimate it.
James Willis, a developer from the Apache Sedona project, contributed in a different way, and that contribution was just as important. Sedona depends on GraphFrames, so he had a direct practical interest in the library being healthy, but he went well beyond passive interest. James reviewed my changes carefully, noticed mistakes I missed, disagreed with me when disagreement was necessary, and did a large amount of the invisible work that makes code actually trustworthy. Review is often treated as secondary compared to authorship. I do not think that is correct. In this case, it was essential.
A lot of code was written by me, yes. But the revival itself was not just code. It needed somebody to push the organizational side until it moved, and somebody else to read the technical work seriously enough to keep it honest. Russell and James did exactly that.
How GraphFrames ended up needing revival
Apache Spark is a distributed data processing engine. GraphX was its older graph API, very much a product of the RDD era. GraphFrames came later and tried to do the same class of work in a more DataFrame-native way, which made it a much better fit for where Spark itself was moving. This is important because the whole revival story only really makes sense against that background. GraphFrames was not just some random external package. It was, at least conceptually, the more modern graph direction in the Spark ecosystem. The awkward part was that by the time GraphX deprecation became a real topic, GraphFrames itself was also in poor shape.A bit of context on Spark, GraphX, and GraphFrames
GraphFrames started as a very ambitious project. It was introduced by Databricks in 2016 as a graph library built on top of DataFrames, which already says a lot about the original intent. This was not a random side package. It was clearly shaped by the broader transition of Spark from the RDD era to the DataFrame era. If one reads the old code and documentation carefully, this ambition is still visible. There are many small artifacts that do not read like “let us keep this forever as an external library on the side”. They read much more like traces of a project that expected a larger future for itself.
The early years were productive. Most of the abstractions that still define GraphFrames today came from that period: the DataFrame-based graph model, conversions to and from GraphX, motif finding, Pregel-style and AggregateMessages-style APIs, and the initial set of graph algorithms. Even now, a large part of the library still stands on that foundation. This is not criticism. If anything, it says that the original design was good enough to survive a long period of weak maintenance. The problem, of course, is that a good initial design does not maintain itself for the next ten years.
What exactly happened after that I do not know, and I do not want to invent a clean explanation where I do not have one. But the public traces are clear enough. Somewhere after the initial burst of development, GraphFrames began to lose momentum. By the early 2020s it no longer looked like an actively evolving graph library. It looked much more like something kept barely compatible with newer Spark versions, often through narrow fixes and workarounds. New features were rare. Old issues accumulated. Stale pull requests accumulated too. A lot of the project’s energy, when there was any, seemed to go not into moving forward but into not falling apart.
From the outside, the whole thing looked awkward in a very specific way. GraphFrames was clearly too useful to disappear, but also not alive enough to keep growing. It had users. It had downstream dependencies. It still occupied an obvious conceptual place in the Spark ecosystem. But it was living mostly on historical momentum. That is a bad state for any library, and especially bad for one that had once looked like the DataFrame-era future of graph processing in Spark.
Then, in late 2024, the discussion around deprecating GraphX exploded on the Spark developer list. This is where the whole situation stopped being merely sad and became impossible to ignore. Holden Karau opened the thread with a very direct observation: GraphX did not seem to have any meaningful active development for more than three years, and bringing it into Spark 4 without actual maintainers looked increasingly questionable.
Since we're getting close to cutting a 4.0 branch I'd like to float the idea of officially deprecating Graph X …
Looking at the source graph X, I don't see any meaningful active development going back over three years* …
Now I'm open to the idea that GraphX is stable and "works as is" and simply doesn't require modifications but … I'm a little concerned here about bringing this API with us into Spark 4 if we don't have anyone signed up to maintain it. – Holden Karau
That would already be enough to make the situation uncomfortable. But then Sean Owen replied with what was, to me, the most important observation in the whole discussion. Yes, one could say that GraphFrames supersedes GraphX. But that only pushes the problem one level further, because GraphFrames itself was also in a bad state: maintained in the loosest sense, but with no serious active development.
I support deprecating GraphX because:
- GraphFrames supersedes it, really
- No maintainers and no reason to believe there will be …
There is one problem: deprecated in favor of what? GraphFrames. But, GraphFrames uses GraphX :) But it is likewise in a similar bucket. Maintained but no active development …
So I think this is kind of "deprecated without replacement". – Sean Owen
That quote captured the whole problem unusually well. It was not just that GraphX was old. It was that the supposed successor was itself in a half-abandoned state, and still partially dependent on the thing it was supposed to supersede. This was not a clean transition. It was a historical knot.
I was reading that thread too. I had been watching GraphFrames for a long time anyway, for a simple reason: I like graphs, as all engineers do, and I have spent most of my career around Apache Spark. So I knew the library, I knew roughly what it was supposed to be, and I also knew that by the end of 2024 it was already in a rather sad condition. But reading that discussion produced a very specific feeling. It was not just “some old library is in trouble again”. It was the much more dangerous thought that this was one of the rare places where I could actually do something real.
I do not mean “real” in a startup sense or in a career-optimization sense. I mean real in the much older and less fashionable sense: useful software exists, people depend on it, the thing is neglected, and the neglect is not inevitable. That is close enough to the GNU Manifesto spirit for me, even if the legal reality here is Apache 2.0 and not copyleft. The point is not the license formula. The point is the idea that if software is genuinely useful, then “nobody is paying for it right now” is not a serious reason to let it decay.
So that thread did not merely catch my attention. It clarified the whole situation. GraphFrames was old, useful, clearly neglected, and still too embedded to ignore. GraphX deprecation made the problem impossible to pretend away. And once I looked at it from that angle, the next step was almost automatic: I stopped looking at GraphFrames as a mildly sad external library and started looking at it as a project that might still be pulled back into a living state.
The next section is about what I found when I looked at it not as a user from a distance, but as somebody trying to make it operational again.
The project was older than it looked
The first problem was almost stupid in its simplicity: the project could not even be imported into an IDE properly because it still depended on sbt 0.13.18, released back in November 2018 (!), which was also the year I entered the IT industry. That alone already told me a lot. A project may look merely “a bit old” from the outside, but once your first real interaction with it is that the build tool itself belongs to another era, the illusion disappears quickly.
The obvious idea was to update sbt first and move on. Of course, that did not work. GraphFrames was still entangled with spark-packages as both a publishing target and a dependency resolver. There was even a dedicated plugin for that, sbt-spark-package, and that plugin itself had last seen activity many years ago. I assume this all made sense at some point. Probably Databricks once saw spark-packages as an important distribution point for the Spark ecosystem, maybe even as the distribution point for Apache Spark itself. But by the time I touched GraphFrames, that whole world was already half-dead. Formally, spark-packages still existed. In practice, it had enormous latency, looked abandoned, and attempts to get any response from support led nowhere.
I came to the project wanting to work on Spark Connect support almost immediately. In practice, however, my first commits were not about Connect at all. They were about fixing the development environment so that serious work could even begin. That was a useful correction of expectations. Before I could touch fresh code or interesting protocols, I first had to make the project stop fighting the person trying to work on it. One thing led to another: outdated CI plugins had to be replaced, new checks had to be introduced, pre-commit had to be added, tests had to start running across matrices and versions instead of surviving by inertia.
Documentation was its own story, and not in a good way. The docs build was based on custom Ruby code, an ancient Docker image, and a fully manual workflow with direct pushes into a branch. This was one of those cases where changing almost anything immediately risked breaking something else, and therefore even the obvious cleanup ideas had to be treated with suspicion. I kept running into the same pattern again and again: what looked like garbage often turned out to be some very old workaround for a piece of infrastructure nobody even remembered anymore. So a lot of the work was not normal refactoring. It was archaeology. You had to first reconstruct what the original problem might have been, then guess why a particular solution was chosen, and only after that decide whether it was safe to touch it.
Only after minimal automation, build cleanup, sanity checks, and general developer experience improvements were finally in place could I actually start doing something useful. I will talk about features later. This section is really about archaeology. And the archaeology could be absurd. At one point I found test code that still carried assumptions from the Spark 1.x era:
// note: not using agg + collect_list because collect_list is not available in 1.6.2 w/o hive
val actualComponents = actual
.select("component", "id")
.as[(T, T)]
.rdd
.groupByKey()
.values
.map(_.toSeq)
.collect()
.map { ids =>
val idSet = ids.toSet
assert(
idSet.size === ids.size,
s"Found duplicated component assignment in [${ids.mkString(",")}].")
idSet
}
.toSetAnd yes, this was still there in 2025. Even Spark 1.6 appears in the comment (released at ∼2015). At that point the code was not merely old. It was carrying around assumptions from a version of Spark that belonged to a completely different epoch. There were many places where the code still dropped down to RDD operations with no real justification anymore. Removing some of those already gave a visible performance boost almost for free.
I believe in continuity, and I still find the old FOSS ideals convincing. So maybe in ten years somebody else will be carefully cleaning up my code and leaving slightly irritated comments about it. That, too, would be a form of success.
Publishing was its own disaster
Still, one of the hardest parts was not code at all. It was publishing. By that point, spark-packages was already more dead than alive, but that was not even the full problem. The much more immediate issue was that nobody had the keys to publish there anymore. Russell kept emailing old maintainers trying to recover access, but as it turned out, they did not have the keys either. So even if spark-packages had been healthy, which it clearly was not, we still could not have relied on it. Moving releases to Maven Central was not an upgrade. It was the only realistic way forward.
And then the real pain began. I had never configured publishing to Maven Central before. Compared to PyPI with trusted publishers, Central is much more complicated, much less forgiving, and much harder to understand if you are doing it for the first time. But even that was not the worst part. The worst part was namespace ownership. We could not get org.graphframes on Central because graphframes.org had already been bought by someone else. I tried, honestly. I wrote to Sonatype support, I wrote a very careful letter, I even used my fancy @apache.org address to look more serious, explained the project history, mentioned the existing users, the GitHub stars, the age of the codebase, the importance of continuity. None of it helped. No domain, no namespace. End of story.
That was one of the first moments when I seriously wanted to quit. This was not how I imagined my involvement in the project. I thought I would be implementing graph algorithms from papers. Instead, I was arguing with Sonatype in the hope of getting a namespace, while simultaneously trying to understand whether publishing under io.graphframes while still using org.graphframes inside the code was even acceptable. Around the 0.9.0 release, I was really close to losing confidence. I felt that I simply did not have enough competence for this kind of work. At the same time, I also understood that without proper releases the project would definitely die. This is the ugly side of maintainership: very often the thing you are least qualified for is exactly the thing that cannot be skipped.
Still, I got through it, and I am honestly proud of that. Once the first release was out, once the release flow became automated, once the development infrastructure stopped being openly hostile, once the stricter linters and basic checks were in place, it became possible to breathe again. For the first time, it felt like GraphFrames might actually survive. I do not think many people realize how close the whole effort was to stalling at that stage. There was no queue of volunteers waiting to take over if I gave up. Quite the opposite. At that point, if I had dropped it, I think the revival could easily have died right there.
You cannot just rewrite it, even if it would be easier
Once the project became at least operational, I could finally move to the part that looked more like engineering in the usual sense: correctness, performance, APIs, actual implementations. But the old constraint returned immediately. In many places, rewriting parts of GraphFrames from scratch would probably have been easier. Sometimes much easier. The problem is that you cannot treat a library like this as greenfield code. It already had users, public APIs, old behavior people were relying on, and enough downstream usage that breaking things casually would have been irresponsible.
The first thing I started looking at was correctness and performance of the core algorithms. One of the simplest things I did was adding LDBC graphs with known outputs into the tests. This is almost embarrassingly basic, but it worked immediately. As soon as there was a stable reference for expected results, several bugs that had apparently lived in the project for years became visible almost at once. This happened more than once during the revival. Old code often does not fail loudly. Very often it just keeps producing some result, and nobody checks carefully enough whether that result is actually correct.
Memory leaks turned out to be a separate and very serious problem. At that point GraphFrames was, for all practical purposes, close to useless for streaming workloads simply because it was too careless with memory. A lot of work went into fixing that. Eventually I reached a more unpleasant conclusion: if I wanted to push this further, GraphX had to be pulled inside GraphFrames instead of being treated as some untouchable external dependency. I did not arrive at this idea because it looked architecturally elegant. I arrived at it because some of the leaks were effectively baked into the implementation and could not be fixed from the outside. They were not just missing unpersist() calls in our code. At some point, if you want control, you have to take control.
That same line of work led to one of the most satisfying fixes in the whole project. While digging through GraphX internals, I fixed one very old quirk in LabelPropagation. The speedup was close to 30x. Almost absurd. This is one of the strange things about legacy work: you can spend days on boring cleanup and nothing visibly changes, and then one old implementation detail finally gives way and the gain is enormous.
Of course, none of this could be done blindly. Once you start touching correctness and performance in an old graph library, intuition is not enough. Memory is not enough either. I needed numbers in front of me. So I had to build benchmarks. That pushed me into the somewhat cursed world of JMH, and then into the even more cursed problem of making JMH behave in a way that is actually useful with Apache Spark. I would not call that part fun. Necessary, yes. Fun, no. But without benchmarks, performance work in a project like this quickly degrades into folklore, wishful thinking, and cargo culting with numbers people vaguely remember from old discussions.
A lot of the work in this phase was also standardization. Old libraries accumulate pointless variation almost automatically. The same conceptual parameter is configured through setters in slightly different ways. Exceptions come from different places. Tests follow different structures because each piece of the code was written in its own era and then left there. I spent a lot of time cleaning this up: shared mixins for common parameters, a single source for exceptions, a simpler and more standardized testing structure, less accidental variation where variation was adding absolutely nothing.
Pregel was an especially delicate case. My changes there felt almost surgical, because Pregel was both a building block and a public API. That is a dangerous combination. If something is purely internal, you can refactor aggressively. If something is purely public, at least the boundaries are clear. Pregel was both. It had to be improved, extended, and optimized, but without casually breaking assumptions people may have built real code around. So a lot of that work was careful rather than flashy. Improve it, but do not break it. Enrich it, but do not change its meaning in the wrong places.
Spark Connect is a newer client-server protocol for Apache Spark. Older Spark APIs were much more tightly tied to the runtime, while Connect forced a cleaner separation between the client-facing API and the actual execution side. For GraphFrames this was important not just because Connect was a new feature to support, but because it forced me to rethink parts of the PySpark API structure that had already become awkward even without Connect.A bit of context on Spark Connect
A similarly large amount of work went into the PySpark API. Spark Connect made this unavoidable. Once Connect entered the picture, the old structure stopped making much sense. What I ended up doing was moving the old implementation logic into a separate layer and leaving the public API at a thinner level: parameterization plus runtime dispatch, basically deciding which implementation to call, classic or connect. This was not only about supporting a new execution mode.
This whole phase was full of moments where rewriting would have been easier. Locally, it often would have been cleaner too. But this is exactly where old OSS becomes interesting. You are not writing a beautiful new system in isolation. You are trying to improve a real one without breaking the trust it has accumulated over the years. That is slower, less elegant, and much more constrained. I still think it is the more honest kind of engineering.
The rewarding part
This was the genuinely rewarding part. After all the archaeology, build fixes, publishing problems, compatibility constraints, and all the other unglamorous things, this was the part that still felt close to the reason I came to the project in the first place. There is a very specific kind of pleasure in reading papers, review articles, or random things found through Google Scholar, trying to locate the one algorithm that can actually survive translation into a MapReduce-style world. You read an iterative update formula, and in parallel your brain is already running a different computation: how many shuffles will this cost, what will the communication pattern look like, and will this thing collapse immediately once it meets a real Spark cluster.
I could give many examples, but a few are enough.
One of the first really enjoyable ones was K-Core. The paper itself was interesting, but what made the implementation memorable was that for the first time I ended up writing fairly low-level Catalyst expressions myself in order to implement the merge logic. This is one of those moments where the pleasant abstraction of Spark disappears and you are suddenly staring at generated code, trying to make peace with the fact that this, too, is now your problem.
ev.copy(code"""
|${leftGenCode.code}
|${rightGenCode.code}
|int ${ev.value} = 0;
|boolean ${ev.isNull} = false;
|int[] $arrayOfElements = ${leftGenCode.value}.toIntArray();
|int $currentCore = ${rightGenCode.value};
|
|int[] $counts = new int[$currentCore + 1];
|for (int $i = 0; $i < $arrayOfElements.length; $i++) {
| int $el = $arrayOfElements[$i];
| if ($el > $currentCore) {
| $counts[$currentCore] += 1;
| } else {
| $counts[$el] += 1;
| }
|}
|
|int $currentWeight = 0;
|for (int $i = $currentCore; $i >= 1; $i--) {
| $currentWeight += $counts[$i];
| if ($i <= $currentWeight) {
| ${ev.value} = $i;
| break;
| }
|}
""".stripMargin)This is the kind of code that looks slightly cursed even when you are the one who wrote it. But this is also what I like about this type of work. You start from a graph algorithm on paper, and if you go deep enough, sooner or later you end up inside Catalyst code generation. That is not the romantic image of distributed systems work, but it is real, and I find it deeply satisfying.
Another major case was Connected Components. This is one of the central algorithms in GraphFrames, and not by accident. If somebody wants to do identity resolution at scale, GraphFrames is still one of the very few practical options I know for billion-scale graphs with thousands of components, many of them looking like long chains, which is exactly where naive approaches become miserable. That is why this work mattered. I spent a lot of time on this part of the library, including improving the old implementation of the Two-Phase approach and getting roughly a 3x speedup by removing parts of the old structure that were preventing Spark from using AQE properly. The Two-Phase paper itself is from the MapReduce world, which is exactly why it was interesting here: it gave a shape that could be translated into Spark without pretending Spark is a PRAM or some fantasy shared-memory machine. The result was not just “one more algorithm” but a better foundation for one of the most important workloads GraphFrames has. The literature around large-scale connected components also led me later to Randomized Contraction, a practical algorithm designed for large distributed data settings and notable for logarithmic-query behavior with high probability.
That later work was rewarding for a different reason. While reading and implementing it, I found myself learning things I had not expected to care about a few weeks earlier, including what an affine transformation \(ax+b\) over a Galois field is and how to make that not completely terrible inside Spark. This is another thing I like in this kind of engineering: the boundary between "software work" and "theory I suddenly need to understand properly" becomes very porous.
And then there was the graph embeddings work, which I enjoyed probably more than anything else in the whole project. The interesting part there was not scientific novelty in the strict sense. I am not claiming I invented a new branch of graph representation learning. The interesting part was that GraphFrames finally got a serious graph-ML-oriented direction that felt native to the project instead of bolted on. Random walks, feature generation, practical embedding pipelines at Spark scale, this was the kind of thing that made the whole effort feel alive again. I wrote more about that separately, so I will not duplicate the whole story here.
Looking back, this section of the work reminded me why I was willing to tolerate the rest. Yes, the publishing infrastructure mattered. Yes, the CI fixes mattered. Yes, backward compatibility mattered. But sooner or later, one also wants the intellectual reward. One wants to open a paper, understand why the algorithm works, then understand why it probably does not work naively on Spark, and then still make it work. That part is a real pleasure. It is slower than people imagine, and more constrained than people imagine, but it is still one of the best kinds of engineering work I know.
The cost of caring
This part is much less pleasant to write about, but leaving it out would make the whole story too clean.
I was emotionally invested in GraphFrames much more than was probably reasonable. And that has a cost. There were periods when I was really close to dropping the whole thing. Not because the work was unimportant, but almost for the opposite reason: because I cared too much, and because the effort required to move the project forward was often wildly out of proportion to the visible response it produced.
The clearest example was the first proper release. I worked on it for more than half a year almost continuously. Not every hour of every day, obviously, but as a long-running burden in the background of life. It was not just code. It was broken infrastructure, publishing, compatibility, testing, release flow, documentation, old assumptions everywhere, and the constant feeling that if I got some part of it wrong, the whole thing would stall again. By the time the release was finally ready, I was close to burned out.
And then I wrote the announcement post. I thought this was a genuinely important event. A ten-year-old semi-abandoned graph library had been brought back to life, releases were working again, development had a future again, the whole thing had survived. I expected at least some real reaction. But almost nothing happened. A few reactions, a few GitHub stars, and that was basically it. I was much more upset by this than I would like to admit. There was a very empty feeling after that. A kind of stupid but real question: was any of this worth it at all?
Something similar happened later with the embeddings work. I spent months implementing Hash2Vec more or less from scratch, wrote what is probably my longest and deepest post about it, and watched it get an order of magnitude less engagement than my much more cynical post about Unity Catalog. That Unity Catalog post I wrote in one evening, right after the release, by taking a raw product and pointing out several places where it was obviously not ready. And of course that performed much better. This is not exactly a shocking discovery about the internet. But it is still unpleasant when one sees it in direct comparison: months of actual engineering and careful writing on one side, one evening of sharp criticism on the other, and the latter gets much more attention.
This can sound petty, so let me be precise. The problem is not that I think good work deserves applause as some kind of entitlement. The problem is that unpaid OSS work has a very weak public feedback loop. If you spend months on a release, on compatibility, on memory leaks, on benchmarks, on code that will quietly make other people’s systems less broken, there is often almost no visible response at all. Meanwhile, hot takes, product criticism, and trendy nonsense are rewarded immediately and predictably. One can say this should not matter. Fine. In practice it still does. At least sometimes.
Over time I got more used to it. Or maybe just more disciplined about not drawing the wrong conclusions from it. I try to orient myself by examples like Stallman, whatever one thinks of him personally. Not because I want to imitate him in every respect, obviously not, but because he represents a type of commitment that I still take seriously: if a piece of software is genuinely useful, that alone can be enough reason to work on it, even if the market does not care, even if the audience is small, even if the response is weak, even if the reward is mostly invisible.
I try to remember that when the whole thing starts feeling pointless. Why am I doing this? Not for engagement, not for a personal brand, not for a product funnel, not because it is the optimal allocation of effort in the eyes of LinkedIn. I am doing it because I still think useful software should exist, and should continue to exist, even when maintaining it is boring, obscure, and emotionally unrewarding much of the time.
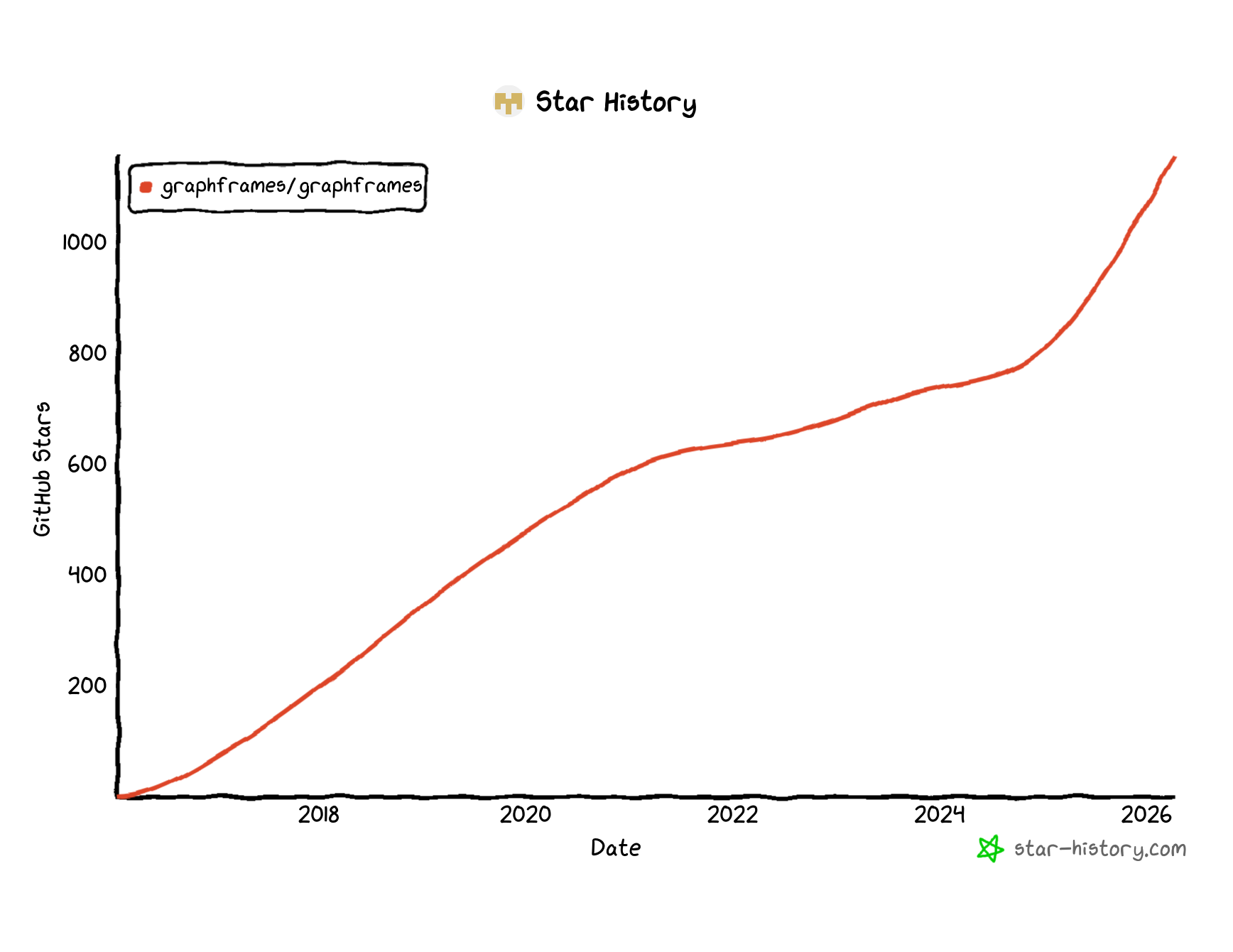
Over time I forced myself to look at the picture more calmly. Projects are simply different. Some barely working, sloppily built, but hype-aligned thing can collect 20k stars in half a day. Fine. That is one kind of project. Then there are projects like GraphFrames. Older, slower-growing, much less fashionable, but actually useful. And if I look at the star history now, I can say one simple thing without false modesty: a substantial part of that later growth happened during the revival, and I do have a right to be proud of that.
What I learned
After a year in the project, after touching almost every important part of it, after going through builds, releases, publishing, docs, tests, APIs, performance, PySpark, GraphX internals, Spark Connect, and actual algorithms, I learned one thing especially clearly: code ownership is not the same thing as authorship.
This sounds almost trivial once stated directly, but people repeat the opposite idea all the time. One often hears that you can only truly own code you wrote yourself. I do not think this is correct. In fact, I think my own experience with GraphFrames is a fairly direct counterexample. I did not write most of this code originally. Much of it was written almost ten years ago by other people, under different assumptions, for a different Spark, for a different moment in the ecosystem. And yet by now I can say without hesitation that I do own it. Not in the legal sense, obviously. In the engineering sense. I understand how the system behaves, where it is fragile, where it lies to you, where it is stronger than it looks, where it can be pushed, and where it absolutely should not be touched carelessly. That is ownership too. In practice, I would say that is the only ownership that really matters.
This feels especially important now, in the middle of all the noise around AI and agentic coding systems. There is a fashionable fear that as engineers write less code directly, ownership will somehow dissolve with authorship. I do not buy that. If anything, the old equation was wrong long before AI. Even the Mozilla.ai piece arguing that ownership is shifting away from authorship explicitly notes that large systems already contained a great deal of code nobody on the team had literally written, and that ownership is better understood as stewardship of behavior over time. My point is simpler and more concrete: this is not some future scenario. This is already how real software works. I own code that I did not write. I had to earn that ownership through maintenance, debugging, release work, refactoring, performance fixes, API cleanup, and enough painful contact with reality. But I earned it.
And this, I think, is a more useful definition of engineering responsibility anyway. Not "I typed these lines myself", but "I understand this system well enough to change it without betraying its users." The second definition is harder. It is also much closer to what maintainership actually is.
More broadly, I learned that legacy OSS is not just old code. It is old expectations, old dependencies, old release processes, old bugs, old habits, and sometimes old pieces of wisdom that still deserve respect. I learned that boring work is not secondary to real engineering. Very often it is the condition that makes real engineering possible at all. I learned that backward compatibility is not a bureaucratic burden but a moral one, especially when software has already been wired into somebody else’s important workflows. And I learned, again, that useful software very often survives not because it is fashionable, but because a few people decide, stubbornly, that it should continue to exist.
I also learned something more positive than all the frustration might suggest. Revival is possible. Not guaranteed, not clean, not fast, and certainly not romantic in practice. But possible. Old code is not dead just because it is old. Sometimes it is merely waiting for somebody to care enough to understand it properly, separate the accidental from the essential, and start moving it again.
So yes, I am tired. Yes, parts of this work were miserable. Yes, there were moments when dropping the whole thing looked like the most rational option. But if I now look at GraphFrames as it exists today, I can also say something simple and positive: it is alive again. More correct, much faster, more modern, much better tested, much more usable, and actually moving. That is enough reason to be glad I stayed with it.
And if I still believe in continuity, then I should probably accept one more thing as well. Maybe ten years from now somebody else will be digging through my code, trying to understand why I wrote it this way, fixing some of it, replacing some of it, and leaving mildly irritated comments along the way. I think that, too, would count as success.