Preface
I would like to thank Andy Grove for his patience while reviewing my work and for his valuable suggestions!
Introduction: Apache Spark
Apache Spark has become the de facto standard for distributed data processing. Since its inception in the 2010s at UC Berkeley, it has grown into one of the largest Apache projects, featuring a huge codebase, hundreds of connectors, and numerous features. It now boasts a mature ecosystem of packages and tools built both on top of and around the project.
Modern Apache Spark is a highly flexible distributed engine capable of handling terabytes of data through SQL or its DataFrame API. Due to its maturity, extensive connectivity options, numerous integrations, and robust design, Apache Spark stands as one of the most generic distributed engines available today. It can handle everything from distributed machine learning and massive graph processing to pure SQL workloads in data warehouse or lakehouse use cases.
No free lunch theorem
As I mentioned before, Spark is very versatile and can handle virtually any data processing task. However, because of this generality, Spark will perform less efficiently than specialized solutions in specific use cases. For example, while you can train distributed machine learning models on Spark, it will be slower compared to dedicated platforms like AWS SageMaker or TensorFlow. Similarly, running data warehouse-like SQL queries on Spark will be less efficient than using specialized tools like Snowflake. For data ingestion, specialized solutions like Apache InLong will likely outperform Spark.
Spark execution model
Apache Spark contains many components, so let's briefly discuss the parts that are important for this post:
- DataFrame API & SQL parsing tool;
- Catalyst planning and optimization tool;
- Physical exucution based on the Internal Row and the code-generation.
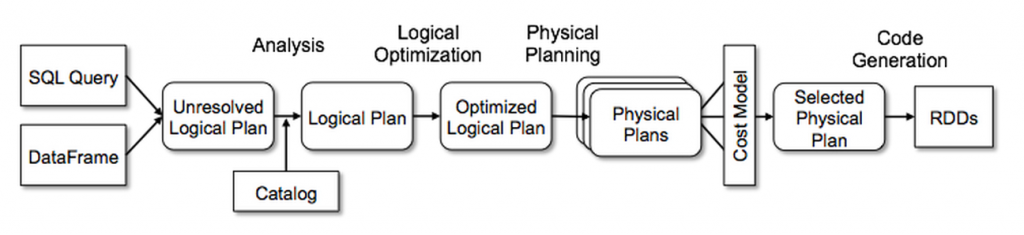
The top level is the DataFrame API (or SQL parsing) that generates an Unresolved Logical Plan, which is essentially a graph of operations as written by the user. Each operation is a node in that graph that may contain children or be a leaf node. When writing a SELECT statement, it becomes a Projection node in the Unresolved plan; a WHERE statement maps to a Filter node, and a FROM statement maps to a Scan node. During the resolution phase, Spark verifies any Scan operations and determines whether the requested columns exist in the source and have the correct data types. During optimization, the Spark Catalyst optimizer applies rules and performs pushdown operations where possible. One example of an optimization rule is when you select a column from a table in a subquery and then select another column from it. Initially, these are two different projection nodes, but they can be merged into a single projection. Similarly, when adding one to a column and then adding two to the result, these two different projections can be merged into a single operation that adds three to the column. Pushdown optimization involves moving filters and projections through the plan to apply them as early as possible, ideally at the Scan level. For instance, if you select two columns from a subquery that originally selected ten columns from a table, the query can be transformed to directly select just the two needed columns. This principle applies to the DataFrame API as well: you don't need to manually select only the columns used in your query because Spark Catalyst can usually determine the required subset of columns automatically. Another example is predicate (or filter) pushdown, where filter expressions can be pushed to the Scan node level, allowing entire groups of rows to be skipped without reading them. For more detailed information on this topic, I recommend reading "How Query Engines Work" by Andy Grove. Another good source on the topic is an article Spark SQL: Relational Data Processing in Spark but I personally found a book from Andy Grove much more easier to understand.
The problem with Spark's approach
NOTE: Most of the thoughts in the following paragraph are not my own but are taken from the paper "Photon: A Fast Query Engine for Lakehouse Systems." I strongly recommend reading this paper even if you are not planning to use Databricks.
Row-oriented data representation in the memory
Due to RDD legacy, Apache Spark is (mostly) relying on the row-oriented data representation in the memory.
NOTE: This is the second time I've mentioned that Spark "mostly" relies on row-oriented data representation, and it seems appropriate to explain what I mean by this. The explanation is that modern Spark also provides an abstraction for columnar execution, but only a few of the existing Spark operators support this feature. Spark's main abstraction for any operator is the SparkPlan. By implementing doExecuteColumnar and setting supportsColumnar to true, one can make an operator accept both row-oriented and columnar-oriented data.
abstract class SparkPlan extends QueryPlan[SparkPlan] with Logging with Serializable {
def supportsRowBased: Boolean = !supportsColumnar
def supportsColumnar: Boolean = false
protected def doExecute(): RDD[InternalRow]
protected def doExecuteColumnar(): RDD[ColumnarBatch]
}Row-oriented representation works best when dealing with naturally row-oriented data, particularly unstructured or semi-structured data. For example, processing raw text, CSV files, or XML files is most efficient using a row-oriented format. However, we are now in an era dominated by columnar open formats such as Apache Parquet, Apache ORC, and their associated metadata frameworks (DeltaLake, Apache Iceberg, Apache Hudi, etc.). In this context, Spark not only loses the benefits of working with columns but must also convert columns to rows before applying any operator. While Spark's implementation of the ColumnarToRow operation is very efficient, it still introduces computational overhead. The same principle applies to data processing itself. For instance, Snowflake uses a columnar execution model similar to the well-known "Monet/X100" system. For typical data warehouse workloads, the columnar execution model is significantly more efficient compared to the row-oriented model. The latter is better suited for handling unstructured data (or transactions in transactional databases, though this isn't relevant for data warehouses designed for analytical queries).
Code generation
NOTE: This topic is a growing area of expertise for me, and I find it challenging to speak confidently about the advantages or disadvantages of virtual function calls compared to code generation. I would like to again reference the article about Databricks Photon, where the authors discuss problems related to the code generation approach.
Spark relies on code generation. When the Catalyst optimizer produces the final Optimized Plan, Spark runs code generation, followed by calls to the Java compiler and JIT compilation. In theory, this approach allows handling very complex cases and leverages modern compilers' branch-prediction techniques. However, in reality, for typical data warehouse analytical workloads, code generation rarely provides advantages over virtual function calls (see the note above). Furthermore, code generation is much harder to maintain, develop, and debug because the final code is only available at runtime. While Spark developer APIs provide a way to access the generated code, developers still need to copy it to a Java file, compile it, analyze the bytecode, and debug it. This process is significantly more complex compared to making calls to kernels that represent operations on columns.
JVM runtime
I often hear that Spark is "slow" because it runs on the JVM. While the JVM does interpret bytecode, through JIT compilation and compiler optimizations, Spark can achieve performance comparable to implementations written in C++ or Rust. In fact, I believe choosing the JVM was one of the keys to Spark's success. For instance, extending Spark by adding a new plugin or data source simply requires implementing a few Java/Scala interfaces. If Spark had been written in C++, any extension would require writing C++ code, which is generally more challenging. Therefore, I disagree with the statement that "Spark is slow because of Java," though there might be some merit to this argument in specific cases.
Cool things about Spark
Most of the criticism above was related purely to Apache Spark's physical execution model. However, the Catalyst optimizer is exceptional and remains one of the best existing optimizers. In my understanding, the PySpark DataFrame API is superior to other existing APIs, and modern tools like Polars or DuckDB are attempting to emulate PySpark's API (rather than Pandas API) because of its excellent design and functionality. Additionally, as previously mentioned, Spark has a vast ecosystem of connectors, plugins, tools, and Platform-as-a-Service offerings.
TLDR of the section
Let's summarize what were wriiten above.
Spark is very cool in terms of:
- Maturity;
- Ecosystem;
- Extendability and APIs;
- Planning and optimization (Catalyst).
At the same time Spark is not so cool in terms of:
- Relying on the code-genration that is hard to develop;
- Relying on the row-oriented data representation that is not well suited for analytical workloads;
- Relying on the JVM for the physical execution.
Photon, Comet, Gluten: taking the best from Spark
Based on the previous section, one can already envision a potential solution: we can take an optimized plan from Spark's Catalyst optimizer and replace the row-oriented JVM physical execution with columnar execution implemented in a language that compiles to native code!
In this case, users can continue to rely on the same PySpark API and connectors while enjoying all the benefits of working with columnar data (SIMD, advantages of columnar table formats, columnar shuffle, and so forth). This approach only requires adding a thin layer on top of the existing extensive Spark codebase. Best of all, no changes to the end user's code are required!
A brief overview of the Gluten and Photon
Apache Gluten (incubating)
An attempt to create a multi-backend Spark plugin. Possible backends include VeloxDB, ClickHouse, and Apache Arrow, among others. In this case, after optimization, the optimized plan is translated from Spark's list of operators to the corresponding list of Velox or ClickHouse operators.

When a Spark operator cannot be translated to a native one, the system falls back to Spark's JVM execution. This fallback mechanism allows support for features like Spark UDFs and some rarely used operators that no one wants to rewrite into native code. A controversal feature of the Apache Gluten is that it allows fallback to spark and switching back to the native execution in any place of the computational plan. I believe that in some cases it may give an advantage but I also agreed with Databricks developers that explicitly mentioned why they did not implement something like this in their Photon engine:
The last node in a Photon plan is a “transition”node. Unlike the adapter node, the transition node must pivot columnar data to row data so the rowwise legacy Spark SQL engine can operate over it. Since Apache Spark’s scan always produces columnar data when reading columnar formats, we note that one such pivot is required even without Photon. Since we only convert plans to Photon starting at the scan node, adding a single pivot on top of a Photon plan does not cause regressions vs. Spark (both the Spark plan and Photon plan each have a single pivot). However, if we were to eagerly convert arbitrary parts of the plan to use Photon, we could have an arbitrary number of pivots, which could lead to regressions. Today, we elect to be conservative and choose not to do this. In the future, we may investigate weighing the tradeoff of the speedup Photon would provide vs. the slowdown caused by adding an additional columnto-row pivot.
Based on the benchmarks provided by the Gluten core team, it shows a performance advantage of approximately 2x compared to the standard Spark runtime. As I can understand, Apache Gluten (incubating) is an engine behind the Microsft Fabric service (Spark PaaS from MS Azure).
Databricks Photon
Databricks, the company founded by Spark's original creators, has made an attempt to improve Spark's performance for data warehouse-like use cases. In my opinion, Photon is the most production-ready among all native runtimes for Spark. However, it is a proprietary solution available exclusively within the Databricks Data and AI platform.
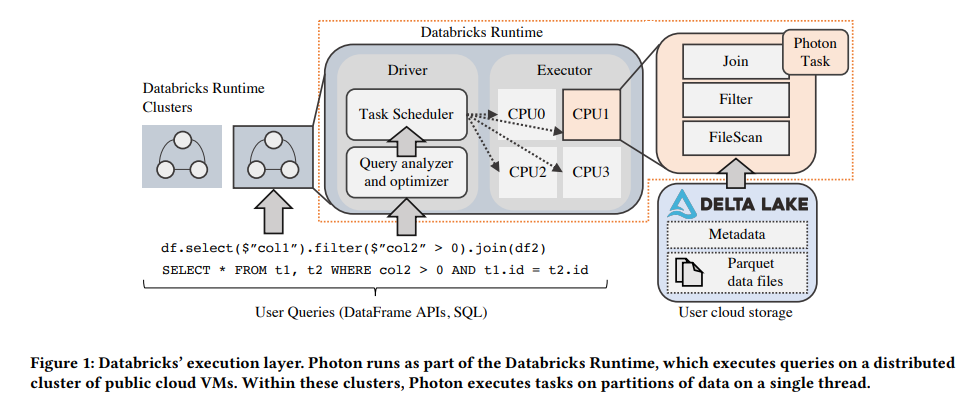
This runtime is written from scratch in C++. I was able to test it because I work for a company that is a Databricks customer. In my experience, Photon can provide up to 3x speed improvement and is particularly efficient when combined with Delta Lake (a metadata layer built on top of Apache Parquet, created and maintained by Databricks).
Apache Datafusion Comet
Apache Datafusion
Before we discuss Comet itself, I need to mention the upstream Datafusion project. It is a Rust-based tool focused on creating an embeddable query engine that uses Apache Arrow as its internal memory model. Currently, it is the fastest among all existing engines for single-node Parquet processing.
While Datafusion itself is not a query engine for end users, it is a solid foundation for building tools. For example, datafusion is the engine behind InfluxDB, Databend, ROAPI, GreptimeDB and many others.
Under the hood Datafusion provides a set of columnar operators, query optimizer and integrtion with data sources.
Datafusion Comet
DataFusion Comet is a project that aims to implement something conceptually similar to Databricks Photon, but using DataFusion as the physical execution layer.
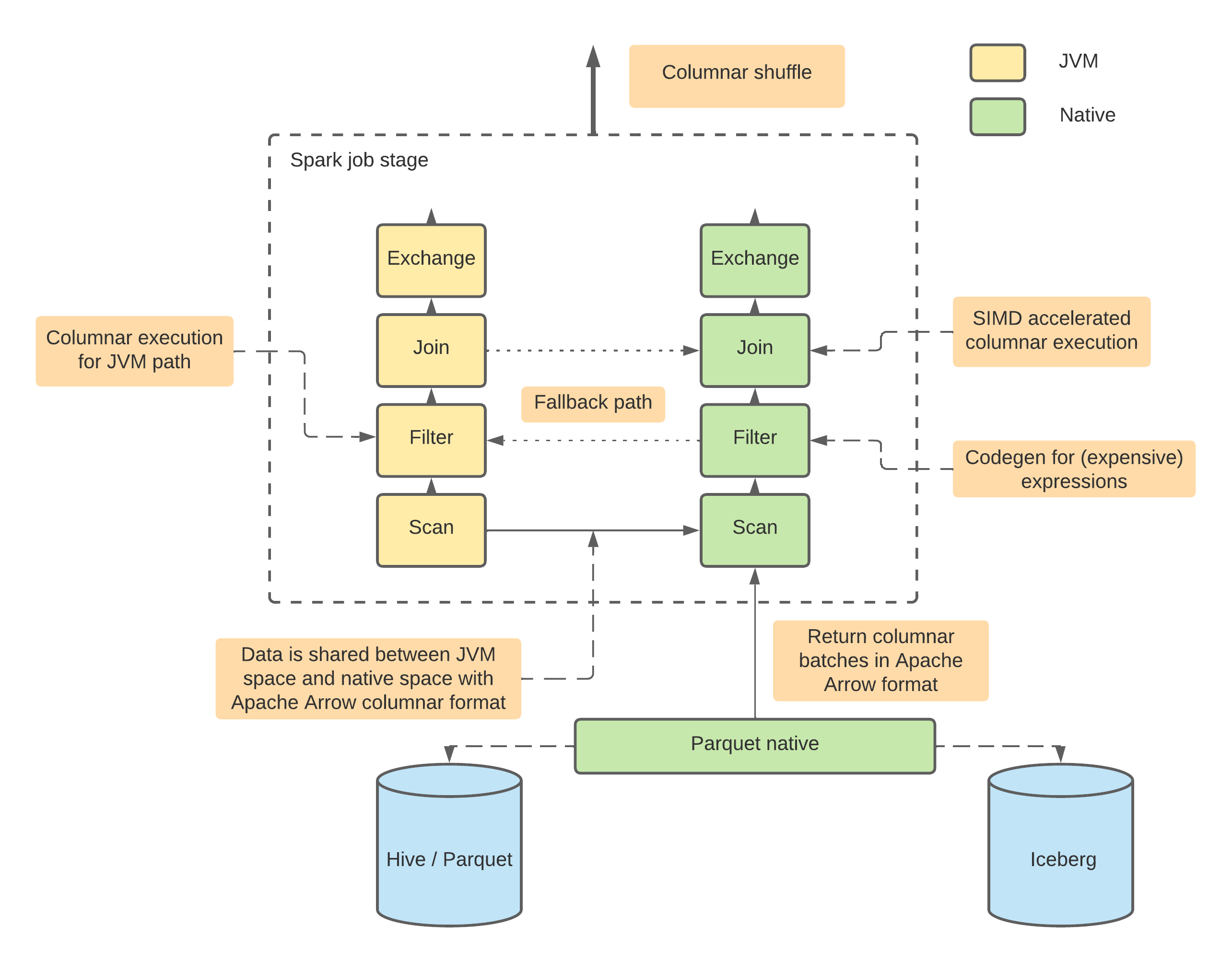
Comet works through org.apache.spark.api.plugin.SparkPlugin:
class CometPlugin extends SparkPlugin with Logging {
override def driverPlugin(): DriverPlugin = new CometDriverPlugin
override def executorPlugin(): ExecutorPlugin = null
}A set of columnar operators
The Comet plan is extending Spark Plan: trait CometPlan extends SparkPlan. On top of that there is a CometExec that implements SparkPlan but always with a supportsColumnar equal to true:
abstract class CometExec extends CometPlan {
def originalPlan: SparkPlan
override def supportsColumnar: Boolean = true
override def output: Seq[Attribute] = originalPlan.output
override def doExecute(): RDD[InternalRow] =
ColumnarToRowExec(this).doExecute()
override def executeCollect(): Array[InternalRow] =
ColumnarToRowExec(this).executeCollect()
override def outputOrdering: Seq[SortOrder] = originalPlan.outputOrdering
override def outputPartitioning: Partitioning = originalPlan.outputPartitioning
def executeColumnarCollectIterator(): (Long, Iterator[ColumnarBatch]) = {
val countsAndBytes = CometExec.getByteArrayRdd(this).collect()
val total = countsAndBytes.map(_._1).sum
val rows = countsAndBytes.iterator
.flatMap(countAndBytes =>
CometExec.decodeBatches(countAndBytes._2, this.getClass.getSimpleName))
(total, rows)
}
protected def setSubqueries(planId: Long, sparkPlan: SparkPlan): Unit = {
sparkPlan.children.foreach(setSubqueries(planId, _))
sparkPlan.expressions.foreach {
_.collect { case sub: ScalarSubquery =>
CometScalarSubquery.setSubquery(planId, sub)
}
}
}
protected def cleanSubqueries(planId: Long, sparkPlan: SparkPlan): Unit = {
sparkPlan.children.foreach(cleanSubqueries(planId, _))
sparkPlan.expressions.foreach {
_.collect { case sub: ScalarSubquery =>
CometScalarSubquery.removeSubquery(planId, sub)
}
}
}
}Columnar shuffle
Comet provides a columnar shuffle as a replacement of the spark itself shuffle mechanics: class CometShuffleManager(conf: SparkConf) extends ShuffleManager with Logging; that allows to translate not only spark expressions (scalar, binary, ternary, etc.) but also such operations like JOIN or GROUP BY!
Protobuf messages
Under the hood, Comet takes a Spark plan and attempts to translate expressions into Datafusion operators where possible. It includes an additional compatibility layer that handles corner cases where Spark results differ from Datafusion. For all supported operators, Comet maintains corresponded protobuf messages:
message Expr {
oneof expr_struct {
Literal literal = 2;
BoundReference bound = 3;
MathExpr add = 4;
MathExpr subtract = 5;
MathExpr multiply = 6;
MathExpr divide = 7;
Cast cast = 8;
BinaryExpr eq = 9;
BinaryExpr neq = 10;
...
BinaryExpr array_append = 58;
ArrayInsert array_insert = 59;
}
}
And in the runtime it looks like this:
def exprToProtoInternal(expr: Expression, inputs: Seq[Attribute]): Option[Expr] = {
...
expr match {
case a @ Alias(_, _) =>
val r = exprToProtoInternal(a.child, inputs)
if (r.isEmpty) {
withInfo(expr, a.child)
}
case cast @ Cast(_: Literal, dataType, _, _) =>
// This can happen after promoting decimal precisions
val value = cast.eval()
exprToProtoInternal(Literal(value, dataType), inputs)
case UnaryExpression(child) if expr.prettyName == "trycast" =>
val timeZoneId = SQLConf.get.sessionLocalTimeZone
handleCast(child, inputs, expr.dataType, Some(timeZoneId), CometEvalMode.TRY)
case c @ Cast(child, dt, timeZoneId, _) =>
handleCast(child, inputs, dt, timeZoneId, evalMode(c))
case add @ Add(left, right, _) if supportedDataType(left.dataType) =>
createMathExpression(
left,
right,
inputs,
add.dataType,
getFailOnError(add),
(builder, mathExpr) => builder.setAdd(mathExpr))
...
}
}Using protobuf in this case provides a single location where all messages are defined and allows us to use code generation with protoc to automatically create serializable Java classes and deserializable Rust structs!
Fallback mechanics
Similar to Photon and Gluten, Comet has a fallback mechanism: if it cannot translate the entire plan to native code, it will translate as much as possible. After that, it applies ColumnarToRow (using Comet's own implementation that leverages Apache Arrow) and execution continues using the Spark JVM engine. Comet follows the same policy as Photon and does not switch back to native execution after fallback due to the overhead costs associated with columnar-to-row and row-to-columnar translations.

Performance
On the TPC-H Comet provides about x2-4 speedup over Spark:

On my own benchmarks in the task of wide aggregations (feature engineering for ML cases) speedup was about x3-x5.
A small step for the open-source but a huge step for myself
Let's conclude the introduction, which is primarily a compilation of information from scientific publications, documentation, and project source code, and move directly to my own contribution to Comet!
I'm a data engineer who has spent most of my career working with Apache Spark, giving me some understanding of its internal workings. I'm also familiar with Spark's source code, as it's common to dive into the source when documentation alone isn't sufficient to solve complex problems. I have experience with Scala and JVM development, having contributed to various Java/Scala projects and even created my own, such as a Spark Connect plugin for the AWS Deequ library. In the same time, like many developers worldwide, I'm very interested in Rust development. Given this background, Comet seems like the perfect project for me. It offers me an opportunity to use my experience and bring some value to the open-source community while learning Rust and Arrow from industry experts. It's worth noting that Andy Grove, a core developer in Apache Datafusion Comet, is also the original creator of arrow-rs.
An issue
Currently, the support for complex data structures like Array, Map, or Struct is limited in the Comet projects. This is understandable, as the core developers prioritize supporting TPC-H queries (data warehouse-like workloads) where nested structures are rarely used. There is an epic marked with "help wanted" regarding the addition of Spark's expressions/operators for complex structures, such as arrays, to Comet. Some of these operators, like array_append, are already supported in Datafusion and the only missing part is a replacing rule in Comet plugin. However, others, such as array_insert, are not supported and need to be implemented from scratch in Comet using Datafusion's abstractions.
I decided to go straight to the "hard-mode" and chose one that should be written from scratch: array_insert.
Spark's implementation
To be honest, I never imagined that implementing such seemingly trivial logic as inserting a value into an array would be so complex. Only after examining the implementation in Apache Spark did I realize the number of different corner cases that needed to be considered. For example: How should negative indices be processed? What happens if the array itself is null? What should occur when the position value is greater than the array's length? Or how should we handle cases where the absolute value of a negative index exceeds the array's length?
Spark implementation:
override def nullSafeEval(arr: Any, pos: Any, item: Any): Any = {
val baseArr = arr.asInstanceOf[ArrayData]
if (positivePos.isDefined) {
val newArrayLength = math.max(baseArr.numElements() + 1, positivePos.get)
if (newArrayLength > ByteArrayMethods.MAX_ROUNDED_ARRAY_LENGTH) {
throw QueryExecutionErrors.concatArraysWithElementsExceedLimitError(newArrayLength)
}
val newArray = new Array[Any](newArrayLength)
val posInt = positivePos.get - 1
baseArr.foreach(elementType, (i, v) => {
if (i >= posInt) {
newArray(i + 1) = v
} else {
newArray(i) = v
}
})
newArray(posInt) = item
new GenericArrayData(newArray)
} else {
var posInt = pos.asInstanceOf[Int]
if (posInt == 0) {
throw QueryExecutionErrors.invalidIndexOfZeroError(getContextOrNull())
}
val newPosExtendsArrayLeft = (posInt < 0) && (-posInt > baseArr.numElements())
if (newPosExtendsArrayLeft) {
val baseOffset = if (legacyNegativeIndex) 1 else 0
// special case- if the new position is negative but larger than the current array size
// place the new item at start of array, place the current array contents at the end
// and fill the newly created array elements inbetween with a null
val newArrayLength = -posInt + baseOffset
if (newArrayLength > ByteArrayMethods.MAX_ROUNDED_ARRAY_LENGTH) {
throw QueryExecutionErrors.concatArraysWithElementsExceedLimitError(newArrayLength)
}
val newArray = new Array[Any](newArrayLength)
baseArr.foreach(elementType, (i, v) => {
// current position, offset by new item + new null array elements
val elementPosition = i + baseOffset + math.abs(posInt + baseArr.numElements())
newArray(elementPosition) = v
})
newArray(0) = item
new GenericArrayData(newArray)
} else {
if (posInt < 0) {
posInt = posInt + baseArr.numElements() + (if (legacyNegativeIndex) 0 else 1)
} else if (posInt > 0) {
posInt = posInt - 1
}
val newArrayLength = math.max(baseArr.numElements() + 1, posInt + 1)
if (newArrayLength > ByteArrayMethods.MAX_ROUNDED_ARRAY_LENGTH) {
throw QueryExecutionErrors.concatArraysWithElementsExceedLimitError(newArrayLength)
}
val newArray = new Array[Any](newArrayLength)
baseArr.foreach(elementType, (i, v) => {
if (i >= posInt) {
newArray(i + 1) = v
} else {
newArray(i) = v
}
})
newArray(posInt) = item
new GenericArrayData(newArray)
}
}
}Only a pure logic of the insertion is about 100 lines of Scala code!
My contribution
Protobuf messages and scala-part
The first step was to define the protobuf message and write an additional case for it in Comet's exprToProtoInternal function:
message ArrayInsert {
Expr src_array_expr = 1;
Expr pos_expr = 2;
Expr item_expr = 3;
bool legacy_negative_index = 4;
}case expr if expr.prettyName == "array_insert" =>
val srcExprProto = exprToProto(expr.children(0), inputs, binding)
val posExprProto = exprToProto(expr.children(1), inputs, binding)
val itemExprProto = exprToProto(expr.children(2), inputs, binding)
val legacyNegativeIndex =
SQLConf.get.getConfString("spark.sql.legacy.negativeIndexInArrayInsert").toBoolean
if (srcExprProto.isDefined && posExprProto.isDefined && itemExprProto.isDefined) {
val arrayInsertBuilder = ExprOuterClass.ArrayInsert
.newBuilder()
.setSrcArrayExpr(srcExprProto.get)
.setPosExpr(posExprProto.get)
.setItemExpr(itemExprProto.get)
.setLegacyNegativeIndex(legacyNegativeIndex)
Some(
ExprOuterClass.Expr
.newBuilder()
.setArrayInsert(arrayInsertBuilder)
.build())
} else {
// boring fallback logic is here
}NOTE: It is interesting that even new functionality added to Spark 3.4 already has its own "legacy mode." I can imagine how challenging it is to maintain Spark: while you can change literally anything, you must first introduce legacy flags before modifying any existing logic!
Create a Datafusion PhysicalExpr for ArrayInsert
The first step was to define a top-level struct that takes all the information from the proto-message and constructs its own state based on this information:
#[derive(Debug, Hash)]
pub struct ArrayInsert {
src_array_expr: Arc<dyn PhysicalExpr>,
pos_expr: Arc<dyn PhysicalExpr>,
item_expr: Arc<dyn PhysicalExpr>,
legacy_negative_index: bool,
}
impl ArrayInsert {
pub fn new(
src_array_expr: Arc<dyn PhysicalExpr>,
pos_expr: Arc<dyn PhysicalExpr>,
item_expr: Arc<dyn PhysicalExpr>,
legacy_negative_index: bool,
) -> Self {
Self {
src_array_expr,
pos_expr,
item_expr,
legacy_negative_index,
}
}
}To create a Datafusion expression, at minimum the following traits need to be implemented for the defined struct:
PhysicalExprDisplayPartialEq
impl PhysicalExpr for ArrayInsert {
fn as_any(&self) -> &dyn Any {
self
}
fn data_type(&self, input_schema: &Schema) -> DataFusionResult<DataType> {
// Datatype checking logic is here
}
fn nullable(&self, input_schema: &Schema) -> DataFusionResult<bool> {
self.src_array_expr.nullable(input_schema)
}
fn evaluate(&self, batch: &RecordBatch) -> DataFusionResult<ColumnarValue> {
// Implementation is here
}
fn children(&self) -> Vec<&Arc<dyn PhysicalExpr>> {
vec![&self.src_array_expr, &self.pos_expr, &self.item_expr]
}
fn with_new_children(
self: Arc<Self>,
children: Vec<Arc<dyn PhysicalExpr>>,
) -> DataFusionResult<Arc<dyn PhysicalExpr>> {
// Not important code is here
}
fn dyn_hash(&self, _state: &mut dyn Hasher) {
// Not important code is here
}
}
impl Display for ArrayInsert {
fn fmt(&self, f: &mut Formatter<'_>) -> std::fmt::Result {
write!(
f,
"ArrayInsert [array: {:?}, pos: {:?}, item: {:?}]",
self.src_array_expr, self.pos_expr, self.item_expr
)
}
}
impl PartialEq<dyn Any> for ArrayInsert {
fn eq(&self, other: &dyn Any) -> bool {
down_cast_any_ref(other)
.downcast_ref::<Self>()
.map(|x| {
self.src_array_expr.eq(&x.src_array_expr)
&& self.pos_expr.eq(&x.pos_expr)
&& self.item_expr.eq(&x.item_expr)
&& self.legacy_negative_index.eq(&x.legacy_negative_index)
})
.unwrap_or(false)
}
}Parsing the message in the native planning
On the native part the first step is to add a rule for the kind of messages I defined:
ExprStruct::ArrayInsert(expr) => {
let src_array_expr = self.create_expr(
expr.src_array_expr.as_ref().unwrap(),
Arc::clone(&input_schema),
)?;
let pos_expr =
self.create_expr(expr.pos_expr.as_ref().unwrap(), Arc::clone(&input_schema))?;
let item_expr =
self.create_expr(expr.item_expr.as_ref().unwrap(), Arc::clone(&input_schema))?;
Ok(Arc::new(ArrayInsert::new(
src_array_expr,
pos_expr,
item_expr,
expr.legacy_negative_index,
)))
}This part was the easiest one from all of my work.
The hardest part: implementation of the logic
NOTE: My implementation is partially based on the array_append implementation in Datafusion, which is distributed under the same Apache 2.0 license.
Following the pattern established in other parts of Comet's codebase, I decided to implement the logic in a separate small function rather than within the body of PhysicalExpr. Throughout my development process, this decision proved beneficial, as it allowed me to easily debug my work using rust-gdb and simple tests for corner cases. In contrast, debugging the logic within PhysicalExpr would have been significantly more challenoging.
Unlike Spark, Apache Arrow (which underlies DataFusion) has two distinct List implementations: List for integer (i32) indices and LargeList for long (i64) indices. Whether Comet should support LargeList remains an open question, since Spark's maximum array length is limited to java.lang.Integer.MAX_VALUE - 15, which aligns with the List implementation rather than LargeList. However, this presents an interesting topic for future research and contribution, which is why my current array_insert implementation is generic in terms of supported arrays.
fn array_insert<O: OffsetSizeTrait>(
list_array: &GenericListArray<O>,
items_array: &ArrayRef,
pos_array: &ArrayRef,
legacy_mode: bool,
) -> DataFusionResult<ColumnarValue> {}Arrays in Apache Arrow
In Apache Arrow arrays are represented in the following way (information from the documentaion):
┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─
┌ ─ ─ ─ ─ ─ ─ ┐ │
┌─────────────┐ ┌───────┐ │ ┌───┐ ┌───┐ ┌───┐ ┌───┐
│ [A,B,C] │ │ (0,3) │ │ 1 │ │ 0 │ │ │ 1 │ │ A │ │ 0 │
├─────────────┤ ├───────┤ │ ├───┤ ├───┤ ├───┤ ├───┤
│ [] │ │ (3,3) │ │ 1 │ │ 3 │ │ │ 1 │ │ B │ │ 1 │
├─────────────┤ ├───────┤ │ ├───┤ ├───┤ ├───┤ ├───┤
│ NULL │ │ (3,4) │ │ 0 │ │ 3 │ │ │ 1 │ │ C │ │ 2 │
├─────────────┤ ├───────┤ │ ├───┤ ├───┤ ├───┤ ├───┤
│ [D] │ │ (4,5) │ │ 1 │ │ 4 │ │ │ ? │ │ ? │ │ 3 │
├─────────────┤ ├───────┤ │ ├───┤ ├───┤ ├───┤ ├───┤
│ [NULL, F] │ │ (5,7) │ │ 1 │ │ 5 │ │ │ 1 │ │ D │ │ 4 │
└─────────────┘ └───────┘ │ └───┘ ├───┤ ├───┤ ├───┤
│ 7 │ │ │ 0 │ │ ? │ │ 5 │
│ Validity └───┘ ├───┤ ├───┤
Logical Logical (nulls) Offsets │ │ 1 │ │ F │ │ 6 │
Values Offsets │ └───┘ └───┘
│ Values │ │
(offsets[i], │ ListArray (Array)
offsets[i+1]) └ ─ ─ ─ ─ ─ ─ ┘ │
└ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─As we can observe, an Arrow array (or List) is composed of three components: an offsets vector, a values vector, and a nulls vector. The values vector is implemented using an Arrow Buffer object, which represents a continuous region of memory. The offsets are used to determine which elements correspond to specific indices in the logical array.
![]()
Actual implementation
Since I already have the original array and the values to insert, I can create a mutable ArrayBuilder object for new values, as well as mutable structures for the new offsets and nulls objects.
let values = list_array.values();
let offsets = list_array.offsets();
let values_data = values.to_data();
let item_data = items_array.to_data();
let new_capacity = Capacities::Array(values_data.len() + item_data.len());
let mut mutable_values =
MutableArrayData::with_capacities(vec![&values_data, &item_data], true, new_capacity);
let mut new_offsets = vec![O::usize_as(0)];
let mut new_nulls = Vec::<bool>::with_capacity(list_array.len());After that, I can iterate over the old offsets and construct a new array value. I will demonstrate only the simplest case where the index to insert is in the middle of the old array. Other cases for negative or large indices are handled similarly, just with a bit more complexity regarding offsets and null values.
for (row_index, offset_window) in offsets.windows(2).enumerate() {
let pos = pos_data.values()[row_index];
let start = offset_window[0].as_usize();
let end = offset_window[1].as_usize();
let is_item_null = items_array.is_null(row_index);
...
let new_array_len = std::cmp::max(end - start + 1, corrected_pos);
if (start + corrected_pos) <= end {
mutable_values.extend(0, start, start + corrected_pos);
mutable_values.extend(1, row_index, row_index + 1);
mutable_values.extend(0, start + corrected_pos, end);
new_offsets.push(new_offsets[row_index] + O::usize_as(new_array_len));
} else {
...
}While it may seem unremarkable, I spent about a week just learning how to work with arrays in arrow-rs. My feelings about that library evolved from "why do people love it so much?" to "wow, how beautiful it is!" At this point, I truly believe the Arrow project is not just code, but a piece of art!
Testing
As primarily a Python developer, I started by defining minimal, simple tests for the native component to address recurring errors like "attempt to subtract with overflow". In Python, I rarely use debugging tools since it's much easier to halt interpretation (for example, in IPython) and analyze the program state - similar to Lisp's REPL-driven development from the 1980s. However, with Rust, this approach isn't possible. Instead, I used rust-gdb for debugging. To my surprise, I found the tool to be remarkably user-friendly and intuitive!
My workflow:
cargo test test_array_insert --no-run
Compiling datafusion-comet-spark-expr v0.5.0 (/var/home/sem/github/datafusion-comet/native/spark-expr)
Compiling datafusion-comet v0.5.0 (/var/home/sem/github/datafusion-comet/native/core)
Finished `test` profile [unoptimized + debuginfo] target(s) in 18.26s
Executable unittests src/lib.rs (target/debug/deps/comet-db43523bbc882879)
Executable unittests src/lib.rs (target/debug/deps/datafusion_comet_proto-0a7e2f643944299d)
Executable unittests src/lib.rs (target/debug/deps/datafusion_comet_spark_expr-0454198feed9fe39)
rust-gdb target/debug/deps/datafusion_comet_spark_expr-0454198feed9fe39After entering rust-gdb, you can debug your Rust program. For example, typing b list.rs:621 will create a breakpoint on line 621 of the file list.rs. Typing run will execute the binary until it reaches the next breakpoint. At the breakpoint, you can use the print command to view the values of various variables. I strongly recommend anyone interested in Rust to try rust-gdb!
The next step was to define end2end tests of the Comet+Spark:
test("ArrayInsert") {
assume(isSpark34Plus)
Seq(true, false).foreach(dictionaryEnabled =>
withTempDir { dir =>
val path = new Path(dir.toURI.toString, "test.parquet")
makeParquetFileAllTypes(path, dictionaryEnabled, 10000)
val df = spark.read
.parquet(path.toString)
.withColumn("arr", array(col("_4"), lit(null), col("_4")))
.withColumn("arrInsertResult", expr("array_insert(arr, 1, 1)"))
.withColumn("arrInsertNegativeIndexResult", expr("array_insert(arr, -1, 1)"))
.withColumn("arrPosGreaterThanSize", expr("array_insert(arr, 8, 1)"))
.withColumn("arrNegPosGreaterThanSize", expr("array_insert(arr, -8, 1)"))
.withColumn("arrInsertNone", expr("array_insert(arr, 1, null)"))
checkSparkAnswerAndOperator(df.select("arrInsertResult"))
checkSparkAnswerAndOperator(df.select("arrInsertNegativeIndexResult"))
checkSparkAnswerAndOperator(df.select("arrPosGreaterThanSize"))
checkSparkAnswerAndOperator(df.select("arrNegPosGreaterThanSize"))
checkSparkAnswerAndOperator(df.select("arrInsertNone"))
})
}Review process
I'm somewhat familiar with how challenging it can be to contribute to high-profile projects like Apache Comet. For instance, my pull request to Apache Spark was ultimately rejected after approximately six months and multiple rounds of reviews that consisted mainly of "fix that" and "fix it" comments (ultimately concluding with "we do not need this feature"). I'm not trying to criticize anyone - I completely understand that while I was attempting to learn and improve my skills, the core developers were focused on their essential work and had limited time available for mentoring contributors.

I was really surprised to receive a review of my initially broken and imperfect PR from a "rock star" Andy Grove less than a week after submitting it! I have no idea how he manages to accomplish so many things while patiently reviewing PRs from people like me. This immediately raised the project's rating by +500 points in my personal evaluation! Thanks again for the patience, Andy! :D
Conclusion
Someone might say, "Why write a long blog post about such a trivial contribution that people do every day?" However, for me, it was a significant challenge. Getting a desired "LGTM" from Andy felt like getting a celebrity's autograph (especially since I had just finished reading his book earlier this year). I'm very proud of this achievement, as I finally contributed something useful not just for myself, but for the entire open source community!
