Preface
I would like to express my gratitude to Matthew Powers for testing my project and providing feedback, and to Steve Russo for offering a valuable review of my code and drawing my attention to avoiding the use of unwrap. Prior to his review, some parts of the code looked like this:
let distr_k = Uniform::<i64>::try_from(1..=k).unwrap();
let distr_nk = Uniform::<i64>::try_from(1..=(n / k)).unwrap();
let distr_5 = Uniform::<i64>::try_from(1..=5).unwrap();
let distr_15 = Uniform::<i64>::try_from(1..=15).unwrap();
let distr_float = Uniform::<f64>::try_from(0.0..=100.0).unwrap();
let distr_nas = Uniform::<i64>::try_from(0..=100).unwrap();
Introduction
H2O db-like benchmark
The H2O db-like benchmark is a suite of benchmarks designed to evaluate the performance of various query engines, particularly those used in data analytics and business intelligence applications. The primary goal of this benchmark is to provide a comprehensive set of tests that mimic real-world workloads encountered in data-intensive environments.
The H2O benchmark suite consists of several components:
- Data Generation: A data generation component that creates synthetic datasets with configurable sizes and characteristics, mimicking real-world data distributions and patterns;
- Query Workloads: A set of predefined query workloads that cover different types of queries, ranging from simple selections and aggregations to complex analytical queries involving window functions, recursive queries, and user-defined functions;
- Performance Metrics: A set of performance metrics that measure various aspects of query engine performance, such as query execution time, resource utilization (CPU, memory, disk I/O), and scalability with increasing data volumes and concurrency levels.
The H2O db-like benchmark is designed to be vendor-neutral and can be used to evaluate a wide range of query engines, including SQL-based engines (e.g., PostgreSQL, MySQL, SQLite), NoSQL databases (e.g., MongoDB, Cassandra), and specialized analytical engines (e.g., Apache Spark, Presto, Dremio).
After being abandoned by H2O, the benchmark repository is now maintained by DuckDB Lab.
Data Generation in H2O db-like benchmark
The data generation in H2O is performed using R scripts and has some limitations.
It is not so easy to run existing R-scripts
The existing R scripts were written in 2018 before the conference and haven't been significantly updated since then. There is no build system or dependency management in place. The project consists of only two long scripts that need to be run via Rscript:
# Rscript groupby-datagen.R 1e7 1e2 0 0 ## 1e7 rows, 1e2 K, 0% NAs, random order
# Rscript groupby-datagen.R 1e8 1e1 5 1 ## 1e8 rows, 10 K, 5% NAs, sorted order
args = commandArgs(TRUE)But if you would try to run the command from the top-level comment in the code you will fail:
Rscript groupby-datagen.R 1e7 1e2 0 0 ## 1e7 rows, 1e2 K, 0% NAs, random order
Error in library(data.table) : there is no package called ‘data.table’
Execution haltedWhile it's not a major issue, it can be particularly frustrating for those who are not well-acquainted with the CRAN system of packages.
NOTE: While this may not seem like a significant problem at first glance, consider the perspective of a database developer who wants to compare their work with others using this benchmark. For Java or C++ database developers, it's likely they are unfamiliar with R, a language primarily used in statistics and scientific research. These developers would need to find a way to install R, troubleshoot potential errors, and use the R scripts as a source of documentation. This process can be time-consuming and frustrating for those not accustomed to working with R.
All the synthetic data should be materialized into memory first
Existing R scripts were created using a simple and straightforward approach. They generate all the data in memory first and only afterward write it to a CSV file.
DT = list()
DT[["id1"]] = sample(sprintf("id%03d",1:K), N, TRUE) # large groups (char)
DT[["id2"]] = sample(sprintf("id%03d",1:K), N, TRUE) # small groups (char)
DT[["id3"]] = sample(sprintf("id%010d",1:(N/K)), N, TRUE) # large groups (char)
DT[["id4"]] = sample(K, N, TRUE) # large groups (int)
DT[["id5"]] = sample(K, N, TRUE) # small groups (int)
DT[["id6"]] = sample(N/K, N, TRUE) # small groups (int)
DT[["v1"]] = sample(5, N, TRUE) # int in range [1,5]
DT[["v2"]] = sample(15, N, TRUE) # int in range [1,15]
DT[["v3"]] = round(runif(N,max=100),6) # numeric e.g. 23.574912
setDT(DT)The main issue is that the system generates all the data first, materializes it, and only then writes it to disk. Consequently, to generate a 50GB dataset, for example, one needs to have at least 50GB of RAM available.
Design of the generator
Most of the design decisions I made have sound reasoning behind them, with one exception - the choice of programming language. I believe that all the project goals could have been achieved by writing the generator in Java or another compiled language capable of optimizing multiple if-else conditions. The main reason I decided to use Rust was that I had read extensively about its unique mechanics and wanted to try it out for myself.
Using Python as a programming glue
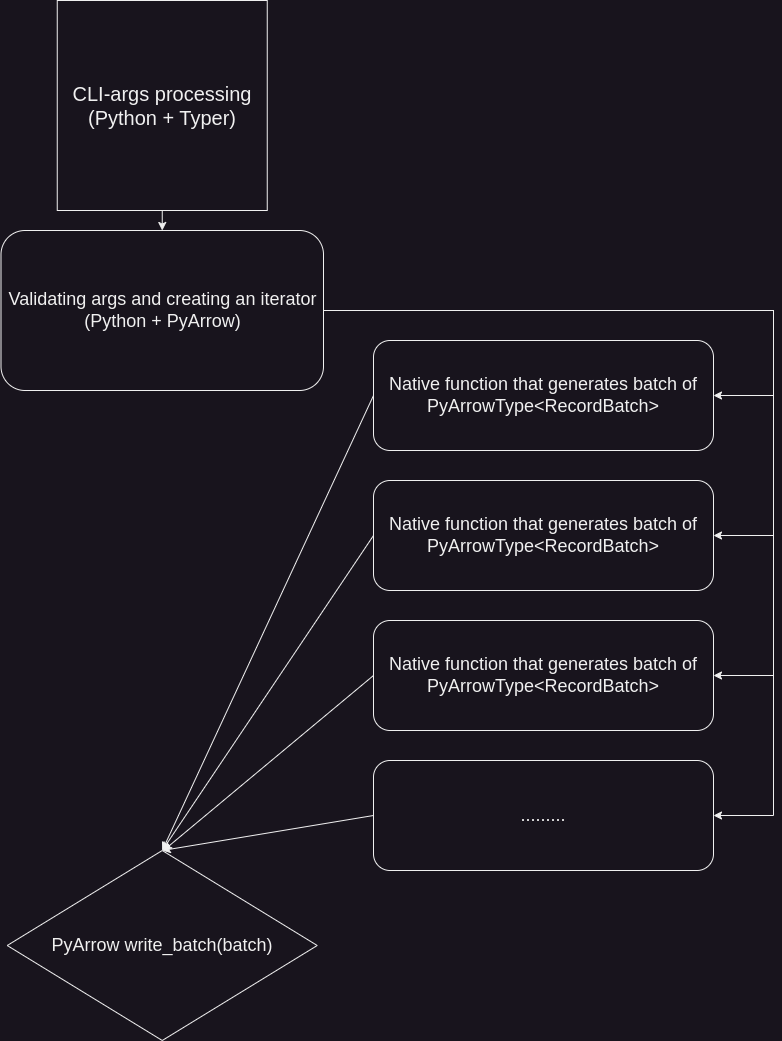
On the other hand, writing logic related to CLI argument parsing, verbosity control, and argument validation can become quite complex in pure Rust. This is where Python, PyO3 and maturin come into play.
PyO3 and Maturin
To be honest, I'm really surprised by how easy it is today to write native functions in Rust and call them from Python using maturin. Maturin is a PEP-compatible Python build backend that generates bindings and places them in Python modules. With just a few lines of code, you can easily transform a Rust function into a Python-callable function.
#[pyfunction]
fn my_best_py_fun(...)
#[pymodule]
fn my_best_py_module(...)The only thing is left is to add a few lines to the pyrpoject.toml (PEP-621):
[tool.maturin]
features = ["pyo3/extension-module"]
python-source = "python"
module-name = "falsa.native"NOTE: A cool feature of Maturin is its ability to generate a project layout and metadata for you based on a template. Simply type maturin new, answer a few questions, and you'll get an almost ready-to-use skeleton that includes a native part, a Python part, Cargo metadata, Python metadata, and even CI/CD configuration!
Why I decided to avoid the global state?
Of course, one doesn't need a cluster to generate 50GB of data. However, what about the case when someone wants to test their solution at a "real" scale and generate 50TB of data? Avoiding the materialization of the entire dataset in memory and using chunk-based techniques mitigates RAM limitations, but it doesn't help with computational time. On the other hand, if we can generate data in chunks, we should be able to generate such chunks in parallel.
To allow not only parallel but also distributed computations, it's important to try to avoid any global state. Otherwise, we would need to address the serialization of such state and worry about synchronization if the state is mutable.
Making generation of the chank as a pure function
In the case of H2O datasets, it is possible to avoid any kind of global state entirely by paying a small price. If we examine the generation logic, we may realize that to generate one chunk of data, we need the following:
- Random seed of the current generation;
- Unique values of the keys to allow join-operation on generated datasets;
If we know the total amount of data we need to generate and the size of each chunk or batch, we can easily pre-generate all the seeds for all the batches using a single global seed. The situation with unique keys is a bit more complex. On one hand, we can pre-generate them once and pass them as an argument to the function that generates a single chunk of data. However, this would make the code much more complex, especially if we plan to implement distributed generation. In the case of distributed generation, we would need to serialize and broadcast such a set of keys.
To simplify the code, I decided to generate keys each time and achieve joinability by using a separate global random seed for keys. This approach adds a small overhead to the generation of each batch of data, so in the future, I may work on improving its serialization.
Arrow and PyArrow
When Matthew asked me to work on that project, he provided some requirements. One of them was the ability to generate files not only in CSV format but also in Parquet (or Delta) format. Apache Parquet is a columnar binary data format that is widely adopted and has replaced CSV files in production processes for quite some time. Delta is a small addition on top of the Parquet format that provides some ACID features by storing a Write-Ahead Log of transactions as JSON files alongside the Parquet files containing the data.
While writing CSV files doesn't require any dependencies, writing to Parquet files without a library can be challenging. Fortunately, there's an excellent project called Apache Arrow that not only provides ready-to-use Parquet (and CSV) writers but also enables zero-copy data exchange between Rust and Python. An arrow::array::RecordBatch created in Rust can be transferred to Python as a pyarrow.RecordBatch without any copying!
Even better, most popular distributed engines, such as Apache Spark, allow working with Arrow data! For example, in Spark, one can create a function that returns a pyarrow.RecordBatch, wrap this function in a UDF (User-Defined Function), and call it via mapInArrow! In that case Spark will handle all the data conversion and scheduling by itself.
By choosing Arrow as a data format, I achieved a state where I can write a pure function in Rust that generates a single batch of data. With such a function, I can proceed in one of the following ways, depending on the task:
- Return the batch of Arrow data to Python and use PyArrow writers to save it to disk in the case of the single-node generation;
- Wrap the batch-generation function to Spark UDF and call it via
mapInArrowin the case of the distributed generartion;
The signature of the native function in such a case looks like this:
#[pyfunction]
fn generate_join_dataset_big(
n: i64,
nas: i64,
seed: i64,
keys_seed: i64,
batch_size: i64,
) -> PyResult<PyArrowType<RecordBatch>>Here variables n and nas are some global parameters of the requested dataset, seed is the random seed for the current batch of data, keys_seed is the random seed for the keys generation and batch_size is an amount of rows the function should return.
NOTE: One might wonder why I'm using only i64 types. The answer is straightforward: Python doesn't have i32 or u64 types, so I decided to pass everything as i64 with an additional validation on the Python side. The details of this validation are described below.
Generation in Rust
Because everything is encapsulated within a pure function and there is no globally shared state, the first step for generation is to define the random generators. I used the rand crate for this purpose.
let mut rng = ChaCha8Rng::seed_from_u64(seed as u64);
let mut keys_rng = ChaCha8Rng::seed_from_u64(keys_seed as u64);
let mut k1: Vec<i64> = (1..=(n * 11 / 10 / 1_000_000)).collect();
k1.shuffle(&mut keys_rng);
let mut k2: Vec<i64> = (1..=(n * 11 / 10 / 1_000)).collect();
k2.shuffle(&mut keys_rng);
let mut k3: Vec<i64> = (1..=(n * 11 / 10)).collect();
k3.shuffle(&mut keys_rng);
let distr_float = Uniform::<f64>::try_from(1.0..=100.0)?;
let distr_nas = Uniform::<i64>::try_from(0..=100)?;
k1 = k1
.get(0..(n as usize / 1_000_000))
.expect("internal indexing error with k1")
.to_vec();
k2 = k2
.get(0..(n as usize / 1_000))
.expect("internal indexing error with k2")
.to_vec();
k3 = k3
.get(0..(n as usize))
.expect("internal indexing error with k3")
.to_vec();These lines may look like magic, but they actually represent the logic from the original R scripts. Before the review, instead of "?", there were endless unwrap() expressions. :)
NOTE: I still have some questions about improved error handling in Rust. For instance, I'm absolutely certain that expect("internal indexing error with k1") is unreachable due to the logic of argument generation and validation. However, I have no idea how to convey this to the Rust compiler.
After obtaining all the required distributions, I need to pre-allocate Arrow vectors for each column of generated data. I created one vector builder per column. The resulting code may look a bit inelegant, but it offers the benefit of significantly simplifying the generation logic for those not sufficiently familiar with Rust.
let item_capacity = batch_size as usize;
let len_of_max_k1_key = (n * 11 / 10 / 1_000_000).to_string().len() + 2;
let len_of_max_k2_key = (n * 11 / 10 / 1_000).to_string().len() + 2;
let len_of_max_k3_key = (n * 11 / 10).to_string().len() + 2;
let mut id1_builder = Int64Builder::with_capacity(item_capacity);
let mut id2_builder = Int64Builder::with_capacity(item_capacity);
let mut id3_builder = Int64Builder::with_capacity(item_capacity);
let mut id4_builder =
StringBuilder::with_capacity(item_capacity, item_capacity * 8 * len_of_max_k1_key);
let mut id5_builder =
StringBuilder::with_capacity(item_capacity, item_capacity * 8 * len_of_max_k2_key);
let mut id6_builder =
StringBuilder::with_capacity(item_capacity, item_capacity * 8 * len_of_max_k3_key);
let mut v2_builder = Float64Builder::with_capacity(item_capacity);The most challenging aspect was determining the capacity for string-column builders. However, because I understand the logic of the generation process and the limits based on input arguments, I was able to accomplish this task successfully.
The creation of random generators and Arrow vector builders is essentially a simple loop from 0 to batch_size. I've given considerable thought to optimizing the code containing multiple if-else blocks. However, after conducting several tests, I strongly believe that the compiler will handle this efficiently through branch prediction techniques. As a result, I've decided to leave the code as it is.
for _i in 0..batch_size {
// We exactly know at the moment that k1, k2, k3 are non empty
let k1 = k1.choose(&mut rng).unwrap();
let k2 = k2.choose(&mut rng).unwrap();
let k3 = k3.choose(&mut rng).unwrap();
if distr_nas.sample(&mut rng) >= nas {
id1_builder.append_value(*k1)
} else {
id1_builder.append_null()
}
if distr_nas.sample(&mut rng) >= nas {
id2_builder.append_value(*k2)
} else {
id2_builder.append_null()
}
if distr_nas.sample(&mut rng) >= nas {
id3_builder.append_value(*k3)
} else {
id3_builder.append_null()
}
id4_builder.append_value(format!("id{}", k1));
id5_builder.append_value(format!("id{}", k2));
id6_builder.append_value(format!("id{}", k2));
if distr_nas.sample(&mut rng) >= nas {
v2_builder.append_value(distr_float.sample(&mut rng));
} else {
v2_builder.append_null()
}
}The final step is to create Arrow vectors from builders and incorporate these vectors into an arrow::array::RecordBatch::try_new(...). Creating an Arrow record batch or table also requires an Arrow Schema object, which should be defined as well.
let schema = Schema::new(vec![
Field::new("id1", DataType::Int64, true),
Field::new("id2", DataType::Int64, true),
Field::new("id3", DataType::Int64, true),
Field::new("id4", DataType::Utf8, false),
Field::new("id5", DataType::Utf8, false),
Field::new("id6", DataType::Utf8, false),
Field::new("v2", DataType::Float64, true),
]);
let batch = RecordBatch::try_new(
Arc::new(schema),
vec![
Arc::new(id1_builder.finish()),
Arc::new(id2_builder.finish()),
Arc::new(id3_builder.finish()),
Arc::new(id4_builder.finish()),
Arc::new(id5_builder.finish()),
Arc::new(id6_builder.finish()),
Arc::new(v2_builder.finish()),
],
)
.unwrap();
Ok(PyArrowType(batch))Working with arrow batches in Python
As I mentioned earlier, Python serves as the programming glue in my project. Writing the logic for argument validation, path generation, and file writing is much simpler in languages like Python. Since the most computationally intensive part is implemented in Rust, there is no performance trade-off. Additionally, my Rust code may appear unsafe in places where I'm converting from i64 to u64. To ensure safety, I validate the arguments in Python before passing them to the native functions.
For example, this part validate numeric values:
NATIVE_I64_MAX_VALUE = 9_223_372_036_854_775_806
def _validate_int64(num: int, prefix: str) -> None:
if num < 0:
raise ValueError(f"Negative values are not supported but got {prefix}={num}")
if num > NATIVE_I64_MAX_VALUE:
raise ValueError(f"Values are passed to native as int64; MAX={NATIVE_I64_MAX_VALUE} but got {prefix}={num}")To separate the generation and writing logic, I created simple wrappers on top of native calls with signatures similar to this:
class GroupByGenerator:
def __init__(
self, size: H2ODatasetSizes | int, k: int, nas: int = 0, seed: int = 42, batch_size: int = 5_000_000
) -> None:
# Some args validation logic is here
...
...
num_batches = self.n // batch_size
batches = [batch_size for _ in range(num_batches)]
# A corner case when we need to add one more batch
if self.n % batch_size != 0:
batches.append(self.n % batch_size)
# Generate a random seed per batch
random.seed(seed)
self.batches = [{"size": bs, "seed": random.randint(0, NATIVE_I64_MAX_VALUE)} for bs in batches]
def iter_batches(self) -> Iterator[pa.RecordBatch]:
for batch in self.batches:
yield generate_groupby(self.n, self.k, self.nas, batch["seed"], batch["size"])This small class has the following responsibilities:
- Validate passed arguments to prevent exceptions in the native code.
- Compute the required number of batches, determine their sizes, and generate a random seed for each batch.
- Provide a method that returns an iterator of
pyarrow.RecordBatchobjects.
Writing the data using PyArrow
Another significant responsibility of the Python component is to provide a user-friendly Command Line Interface (CLI). To achieve this, I utilized Typer, a library created by the author of FastAPI. I won't dive into the details of this part, as it primarily consists of routine if-else statements and error handling for various cases and scenarios. The overall CLI logic for generating four types of H2O datasets, with the ability to save results in three different formats (CSV, Parquet, and Delta), comprises approximately 350 lines of code. You can check the sources here if you are intereting.
I will cover only some parts of the CLI that were interesting to work on. For CSV and Parquet formats, implementation was quite straightforward because the built-in PyArrow writers are very effective and provide full support for batch-writing without materializing the entire dataset in memory. With PyArrow, I don't even need to handle the batch-writing logic myself.
Fo example, parquet logic looks like this:
if data_format is Format.PARQUET:
writer = parquet.ParquetWriter(where=output_big, schema=schema_big)
for batch in track(join_big.iter_batches(), total=len(join_big.batches)):
writer.write_batch(batch)
writer.close()Delta problems
The most challenging aspect was writing to the Delta format. Initially, it appeared to be a straightforward task due to the delta-rs project, which offers Python bindings. This project provides a method called write_deltalake with the following signature:
write_deltalake(
table_or_uri: Union[str, Path, DeltaTable],
data: Union[pd.DataFrame, ds.Dataset, pa.Table, pa.RecordBatch, Iterable[pa.RecordBatch], RecordBatchReader, ArrowStreamExportable],
*,
schema: Optional[Union[pa.Schema, DeltaSchema]] = None,
...
) -> NoneThis method initially appeared to offer a simple solution for writing to the Delta format. At first glance, I thought it supported writing batches without materializing the entire dataset, as it accepts Iterable[pa.RecordBatch]. Unfortunately, even when passing an iterator to this method, it still triggers materialization. Since avoiding materialization and RAM issues was the main motivation for the entire project, this approach proved unacceptable.
I tried many different approaches, including asking a question in the Delta Slack channel, but I couldn't find a solution for using delta-rs to write batches. Ultimately, I decided to avoid using delta-rs in my project altogether and attempted to implement Delta writing myself. This decision was based on the fact that Delta is essentially just JSON metadata on top of Parquet files, and I already know how to write Parquet files effectively.
The Delta protocol is not particularly difficult or complex, especially if you don't need advanced modern features and simply want to convert Parquet files to Delta. In this case, all I needed to do was create JSON files that represent Write-Ahead Log of transactions. The following code accomplishes exactly this task:
PA_2_DELTA_DTYPES = {
"int32": "integer",
"int64": "long",
}
def generate_delta_log(output_filepath: Path, schema: Schema) -> None:
"""Generate a delta-log from existing parquet files and the given schema."""
file_len = 20
delta_dir = output_filepath.joinpath("_delta_log")
delta_dir.mkdir(exist_ok=True)
add_meta_log = "0" * file_len + ".json"
with open(delta_dir.joinpath(add_meta_log), "w") as meta_log:
jsons = []
# Generate "metaData"
jsons.append(
json.dumps(
{
"metaData": {
"id": uuid4().__str__(),
"format": {
"provider": "parquet",
"options": {},
},
"schemaString": json.dumps(
{
"type": "struct",
"fields": [
{
"name": field.name,
"type": PA_2_DELTA_DTYPES.get(field.type.__str__(), field.type.__str__()),
"nullable": field.nullable,
"metadata": {},
}
for field in schema
],
}
),
"configuration": {},
"partitionColumns": [],
}
}
)
)
# Generate "add"
for pp in output_filepath.glob("*.parquet"):
jsons.append(
json.dumps(
{
"add": {
"path": pp.relative_to(output_filepath).__str__(),
"partitionValues": {},
"size": pp.stat().st_size,
"modificationTime": int(time.time() * 1000),
"dataChange": True,
}
}
)
)
# Generate "protocol"
jsons.append(json.dumps({"protocol": {"minReaderVersion": 1, "minWriterVersion": 2}}))
meta_log.write("\n".join(jsons))Although it may appear inelegant, I didn't need to implement the entire protocol. Since I only required it for the simple operation of converting Parquet to Delta format, this approach was sufficient.
Conclusion
In this blog post, I describe one of my first attempts to create something useful in Rust. Previously, I had primarily worked with Python and JVM languages like Java and Scala. It was a very interesting experience. The project is now available on PyPI; you can install it using pip and try it out!
$ pip install falsa
$ falsa --help
Usage: falsa [OPTIONS] COMMAND [ARGS]...
H2O db-like-benchmark data generation.
This implementation is unofficial!
For the official implementation please check https://github.com/duckdblabs/db-benchmark/tree/main/_data
Available commands are:
- groupby: generate GroupBy dataset;
- join: generate three Join datasets (small, medium, big);
Author: github.com/SemyonSinchenko
Source code: https://github.com/mrpowers-io/falsa
╭─ Options ─────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ --install-completion Install completion for the current shell. │
│ --show-completion Show completion for the current shell, to copy it or customize the installation. │
│ --help Show this message and exit. │
╰───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ Commands ────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ groupby Create H2O GroupBy Dataset │
│ join Create three H2O join datasets │
╰───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯