TL;DR
Yes, I really ended up running headless Emacs in Docker Compose. Yes, it actually works. And yes, this post is about why I think this setup makes much more sense than it sounds.
What I wanted was not another AI toy, not a generic framework, and not a startup idea. I wanted a piece of personal software built around my own workflows: quick notes from mobile, automatic extraction of TODOs, periodic digests, light planning, and adding useful things into a second brain. In other words, I wanted a productivity system with AI inside it, but shaped around my own data, habits, and trust assumptions.
This is why the stack ended up looking slightly insane. Org Mode gives me not just one plain-text model for notes and tasks, but one common format for the whole system. Emacs, weird as it may be in this role, is still the most complete runtime for working with Org files. And LLMs play two different roles here. They are part of the system itself, but only inside bounded workflows orchestrated by deterministic code, and they are also the reason this project became realistic for me to build at all.
So this is also a post about something larger. LLM coding does not only generate demos and generic AI products. It also makes it much easier to build narrow, deeply personal software that would previously be too expensive to write by hand. I would probably never have written several thousand lines of hardcore Lisp for a project like this on my own. With AI assistance, however, this kind of strange but useful infrastructure became possible.
Before Anyone Gets the Wrong Idea
I should probably clarify a few things before going further.
I use Emacs, but I am very far from being an Emacs wizard. I am not even sure I would call myself a power user. For a long time I used Spacemacs, and more recently I moved to an LLM-generated configuration that reproduces the parts of Spacemacs I actually needed without all the extra weight. I can usually read Lisp if I have to, and with enough time I can understand what is going on. But it is slow, uncomfortable, and definitely not my native environment. Writing non-trivial Emacs Lisp on my own is, realistically speaking, almost out of the question.
At the same time, I am not approaching this project as a random person with a prompt window. I work as an engineer in Data and ML related areas, so I do have a reasonable idea of what LLMs can and cannot do. I also have some real experience building enterprise solutions around LLMs. More generally, I have a normal software engineering background and a decent understanding of how systems are supposed to behave: race conditions, conflicts, boundaries, client-server interactions, Docker, atomicity, and all the usual boring things that become very non-boring when they are ignored.
This is also the right place to say something else clearly: the whole project discussed in this post was vibecoded. I use this word deliberately. But by vibecoded I do not mean that I wrote “please build me a personal assistant” and then watched an agent hallucinate a codebase into existence. What I mean is dozens of iterations, a lot of OpenSpec files, explicit boundaries and constraints, a strong bias toward tests, and constant auditing of both the generated code and the system behavior. The AI did a lot of the typing and a lot of the local problem solving. It did not replace engineering judgment, and it definitely did not make trust boundaries disappear.
Why Not OpenClaw?
This question is better answered immediately, so that I do not need to return to it later.
I do not trust LLMs with orchestration. I do not mean that I dislike them, or that I think they are useless. I use them a lot. But I do not trust them as the control plane of a personal system that has write access to my real notes, my personal knowledge base, my task lists, and eventually all the other things that make such a system actually useful.
The reason is simple. Agentic orchestration is too unreliable, too non-deterministic, and too open-ended for this kind of job. Once a model is allowed to drive the loop itself, choose its own next actions, mutate state freely, and reinterpret instructions on the fly, the state space becomes far too open. At that point I do not have a tool anymore. I have a stochastic process with filesystem access.
This is not a theoretical concern. In February 2026, TechCrunch reported on a now widely discussed story in which Meta AI security researcher Summer Yue said an OpenClaw agent, after being asked to help with email cleanup, started deleting messages from her real inbox and ignored stop instructions sent from her phone. TechCrunch noted that it could not independently verify the exact details, but the broader point is still the one that matters to me: prompts are weak guardrails, context handling can drift under load, and agentic systems aimed at real personal workflows are still very capable of going off the rails in ways that are both boring and destructive.
This is exactly the class of failure I do not want to normalize. I am not interested in giving a model broad authority over my real personal data and then hoping that a long enough system prompt, a memory file, or a better stop command will save me when something goes wrong. Maybe this class of systems will become trustworthy enough later. Today, I do not believe that.
So my design choice is very explicit. The LLM is a tool, not the orchestrator. The loop is closed by deterministic code. The places where the model is allowed to act are narrow, explicit, and bounded. It can transform text, classify things, summarize things, or suggest structure inside a predefined workflow. It does not get to decide what the workflow is, what the safety boundaries are, or how far it is allowed to go.
This is why I do not see OpenClaw-like systems as direct alternatives to what I am building. They belong to a different category. They are trying to build autonomous personal agents. I am trying to build personal software with some carefully constrained LLM automation inside it. These are not the same thing.
Software I Always Wanted to Have
What I really want is not just note-taking software, and not just a TODO app with some AI checkbox added on top. What I want is to use LLMs to automate parts of my own daily workflows.
For example, I often use LLM WebUIs to summarize articles and websites and then turn them into notes. This already works, but in a very manual and fragmented way. If I read a good blog post on my phone, I usually save it somewhere first, then later open it on my laptop, run it through an LLM, generate a summary, and only then add the link and the note into my personal knowledge base. This is already useful. But it also feels like exactly the kind of workflow that should be much easier to automate.
The same thing happens with feeds. When I browse RSS or Atom subscriptions, I usually scroll through titles in some UI, open interesting entries, push them through an LLM to see whether they are actually worth deeper reading, and then, if they are, I may save them again somewhere else for later. This is not hard, but it is repetitive, and it is exactly the kind of repetitive text-heavy workflow where LLMs are actually useful.
TODOs and planning are another example. AI-driven task management and day planning sound nice on paper. In practice, they usually require a lot of discipline from the user. Tasks need tags, priorities, categories, deadlines, and other metadata. And of course this is exactly where one starts losing motivation. So the obvious question is: if a model can often infer tags, suggest priorities, and help with planning from the current task list and some context, then why should I manually maintain all of that structure every time?
So the kind of software I always wanted to have is fairly specific. I want LLMs inside it, but on my own terms, with my own provider choices and ideally BYOK. I want a decent mobile interface, but also a web interface and a desktop client. I want notes, TODOs, digests, second-brain workflows, and LLM-assisted automation to live in roughly one system instead of five disconnected ones. I want privacy, control over data, and as little vendor lock-in as possible.
I do not know a single existing solution that really closes this whole gap for me. In theory, one can assemble a zoo of self-hosted tools. In practice, each of them comes with its own flow, its own assumptions, its own half-configurable boundaries, and usually very limited support for the kind of LLM automation I actually want, especially with BYOK. And yes, in theory one can always write such a system from scratch. But unless this becomes your actual job, it is a huge amount of work for a personal project, and it is very easy to lose motivation long before the thing becomes genuinely useful.
This is where the current state of LLM coding actually matters. Not because it makes software design unnecessary, and not because agents magically know what I want, but because it changes the economics of personal software. If I know quite well what I want and how it should behave, then building something narrow, weird, and deeply customized becomes much more realistic than it used to be.
Why Plain Text and Org Mode
The first design choice here was not actually about Emacs. It was about plain text.
For this kind of system, plain text is unusually hard to beat. I am not building a multi-tenant SaaS, not a high-scale collaborative platform, and not some enterprise knowledge graph with five abstraction layers on top. I am building a deeply personal system for one user. In that situation, I care much more about inspectability, editability, backup, sync, portability, and low operational complexity than about fashionable infrastructure.
Plain text gives me exactly that. I can read it directly, diff it, grep it, back it up, version it, sync it, and in the worst case fix it by hand. It is also a very natural interface between the human side of the system, the deterministic code, and the LLM layer. I read and write text. The system reads and writes text. The LLM also consumes and produces text. This does not make the model trustworthy, of course, but it does reduce the amount of translation, hidden state, and unnecessary machinery in the loop.
At the same time, plain text alone is not enough. If all I had was a directory of random Markdown files, I would very quickly run into the exact problem I wanted to avoid. Notes are easy. But once one wants TODOs, priorities, deadlines, scheduling, links, metadata, capture flows, and a second brain in one system, “just text files” stop being enough. One needs structure, conventions, and semantics.
And this is where I think Org Mode is still in a very special position.
Org is not just a markup language. It is a whole operational model for personal information. It already knows what a TODO is. It already knows what a deadline is. It already knows what scheduling is, what priorities are, what tags are, what properties are, what capture and agenda workflows are. In other words, a lot of the hard semantic work is already there.
This matters much more than it may seem at first. If I tried to build the same kind of system on top of Markdown, I strongly suspect I would eventually end up reimplementing Org Mode badly inside Markdown conventions. First I would add task syntax. Then priorities. Then deadlines. Then some metadata format. Then rules for planning. Then some way to represent machine-generated notes and digests. Then some conventions for links and inboxes. And after enough iterations I would have a pile of files that still look like Markdown, but behave like a poor substitute for Org.
That is the core reason why Markdown did not look convincing to me here. It is not that Markdown is bad. It is that the Markdown ecosystem is fragmented exactly where I needed coherence. For notes, there are many good options. For tasks, scheduling, and structured personal workflows, one usually ends up with a plugin stack, a set of conventions, and a lot of informal glue. This may be perfectly fine for many people. But for the kind of system I wanted, it felt like building on top of a moving pile of semi-compatible assumptions.
There is also one more important piece here: org-roam. A second brain is a very real part of what I wanted, and org-roam already gives a lot of that out of the box. It is explicitly a plain-text personal knowledge management system, with backlinks, graph visualization, and an ecosystem around it. It is also private and offline-first by design, which matters a lot to me. With Markdown tooling, I would most likely end up with one stack for notes, another stack for tasks, and then some extra layer for knowledge graph features. With Org and org-roam, much more of this lives in one world.
This also matters on the publishing side. These days it is fairly common to have some kind of public second brain, and Org fits that model well too. In my case, I already use a GitHub Pages build from org-roam notes. So the same ecosystem that gives me private notes, tasks, and automation also gives me a path to publish selected knowledge publicly without inventing yet another content pipeline.
Org Mode gives me something stronger than just “notes plus tasks”: it gives me one common format for the whole system. Not just for notes and TODOs, but for rules, inboxes, generated artifacts, and other operational surfaces. In practice, this means I can store logs in Org files, keep planner rules in Org files, keep feed lists in Org files, and even represent some classes of errors as high-priority overdue TODOs that mobile Org clients surface as notifications. This is the kind of thing that sounds slightly ridiculous until one notices that it removes a surprising number of moving parts.
This is also where the ecosystem matters. Because Org semantics are rich and widely supported, I do not need a separate custom UI for every little subsystem. A client that can work with Org files is already useful. Emacs works, of course. Orgzly works well enough on mobile. There are also other mobile clients around the ecosystem. And if I want a browser-based interface, there is even Organice, which is an implementation of Org mode for mobile and desktop browsers and syncs with storage backends such as WebDAV. In the worst case, even a dumb text editor still lets me inspect the source of truth directly (VSCode as an example). At that point the system becomes surprisingly client-agnostic. The clients may differ in comfort, but they all speak the same language. And because the source of truth is still just a set of files I own, this also means there is no real vendor lock-in hiding underneath the UI.
So for me, the combination of plain text, Org Mode, and org-roam was not a nostalgic or ideological choice. It was the most practical way to get one durable, inspectable, automation-friendly format with enough semantics to support notes, tasks, scheduling, digests, a second brain, and the rest of the workflows I actually cared about. Everything else in this project follows from that decision.
How Did I End Up with Emacs in Docker?
This part sounds much crazier than it actually is.
Once I decided that plain text and Org Mode would be the foundation, the server-side question became much narrower. I did not need a high-load backend. I did not need protobuf schemas, a complicated database layer, horizontally scalable workers, or any of the usual production machinery people instinctively reach for. I needed a not too demanding daemon that can sit quietly in the background, process files, run scheduled jobs, talk to LLM APIs, and most importantly understand Org syntax fully and correctly.
If Org files are not just the source of truth, but also the input queue, the lightweight UI, the logging surface, the error surface, the rules layer, and part of the configuration, then the runtime question changes quite a lot. At that point I do not want something that understands Org approximately. I want the thing that actually speaks Org natively, which in practice means the reference implementation.
And this is where the answer became both strange and obvious: Emacs and Emacs Lisp themselves.

There are parsers for Org in other languages, of course. But from what I have seen, they are usually partial, incomplete, or good enough only until one starts relying on more advanced parts of the syntax and workflow. A partial parser is fine for import and export. It is much less fine when the whole system lives inside the format. This may be perfectly acceptable if Org is just one format among many. But that is not what I wanted here. I wanted the system to speak Org natively, not approximately.
So the logic was surprisingly simple. I needed full Org support. Emacs already has it. Emacs can run as a daemon. My workload is small enough that I do not care about squeezing every last drop of performance out of the runtime. Therefore, headless Emacs in Docker.
Yes, this sounds slightly insane. I am aware of that. I also have not really seen many examples of people using Emacs in exactly this role, as a self-hosted backend for personal automation. But once I stopped comparing it to generic backend stacks and started comparing it to the actual requirements of this project, it became hard to argue against.
I do not need Emacs here because I want to be clever. I need it because I do not want to spend months reimplementing Org behavior badly in another language. The alternative was not some clean, modern, respectable backend magically solving the problem. The alternative was me slowly rebuilding a subset of Org semantics outside Emacs, with more code, more bugs, and less confidence in the result. I do not find that attractive.
There is also one more practical point. Emacs is weird, but it is not especially heavy for this kind of job. A single-user daemon that watches files, runs scheduled processing, talks to LLM APIs, and rewrites Org files does not need to be a performance monster. In this particular niche, “good enough and semantically correct” matters much more than “modern-looking and theoretically scalable.”
So this was not really a case of choosing the most fashionable server runtime. It was a case of asking a much narrower question: what is the least absurd way to get full Org semantics, low operational complexity, and a background process that can quietly run my workflows? Somewhat to my own surprise, the answer turned out to be Emacs in Docker.
There was also one more strong argument in favor of Emacs Lisp here. Since I already expected a large part of the implementation work to happen through LLM-assisted coding, the choice of language started to matter in a slightly different way. Emacs Lisp is a small, compact language, and like Lisp languages in general it is unusually machine-friendly. The syntax is regular, the surface area is not huge, and generated code is often easier to inspect than in heavier languages with more ceremony. On top of that, there are decades of open-source Emacs Lisp code available in the wild. And while nobody outside model vendors knows the exact contents of training corpora, I think it is a fairly safe assumption that modern LLMs have seen enormous amounts of open-source code, including a lot of Emacs Lisp, regardless of what various licenses may have tried to say about that. So in this case the weird runtime and the weird language ended up reinforcing each other.
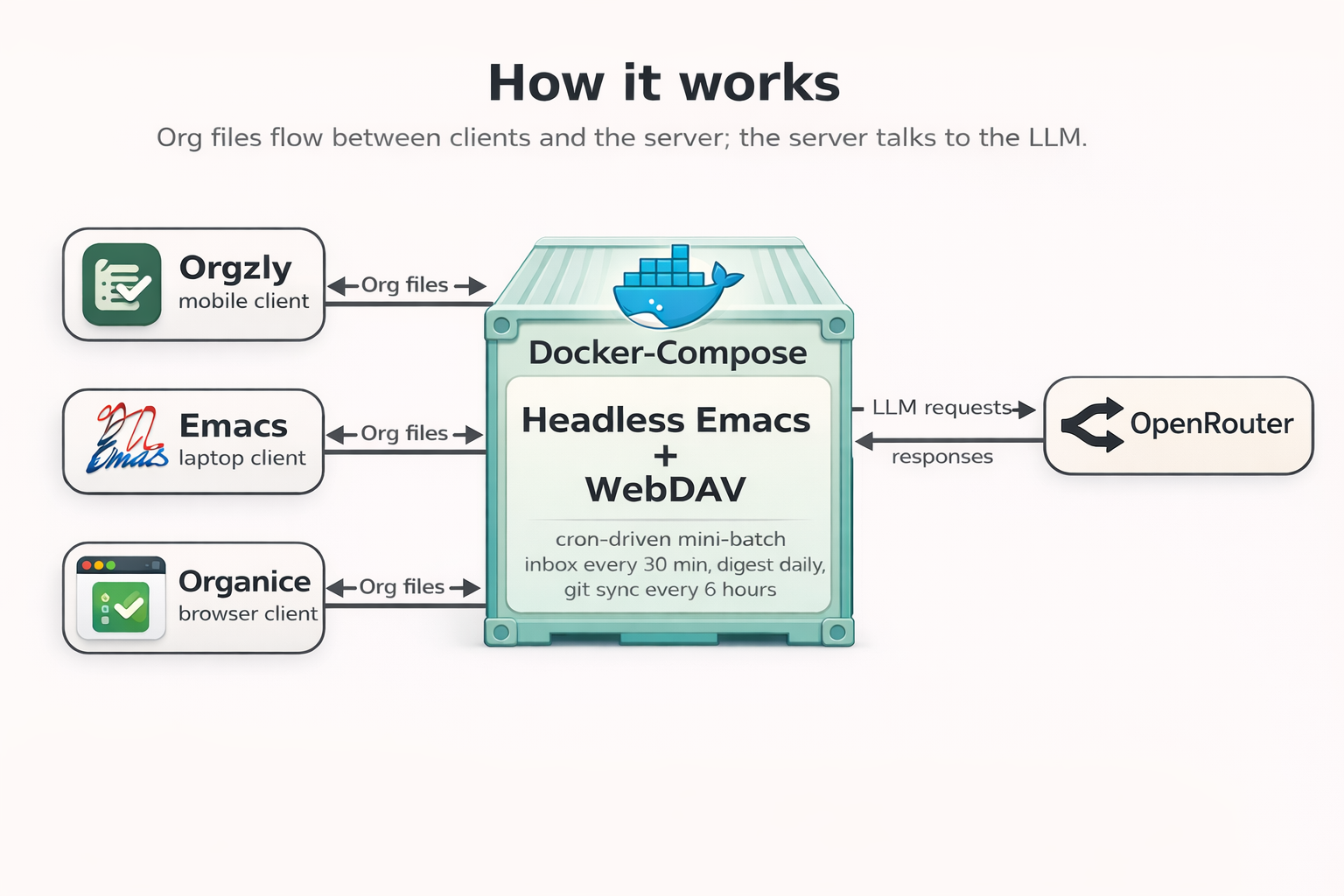
How It Works
The whole system is intentionally built as a small cron-driven mini-batch service, not as a real-time one.
This was a conscious choice. First, I do not think real-time processing is actually needed here. For a personal system, running every 30 minutes is usually more than enough. Second, real-time would make the whole thing much more fragile. If the client side is DAV-based and intentionally client-agnostic, then real-time starts meaning file watching, conflict handling, atomicity problems, lock propagation, and various edge cases around partially synced files. And that gets ugly very quickly, especially if one does not write a custom mobile client and instead relies on WebDAV clients such as Orgzly, Organice, rclone mounts, and similar tooling. Third, real-time code built with heavy LLM assistance would be much harder to trust and much harder to test properly. So I did not try to build that system.
In practice, Docker Compose runs only a few things: Emacs, Apache WebDAV, and Certbot for periodic certificate renewal. Inside Emacs, the daemon mostly sleeps, and cron wakes it up for specific workflows. This is enough for my use case.
Right now the main scheduled jobs are these. Every 30 minutes, the current inbox-mobile.org is processed. Once a day, an RSS or Atom digest is generated. Every 6 hours, the current org-roam snapshot is pushed to git, while periodic pulls also happen via cron. There is also a health probe on cron, and a daily purge of cursors and logs so they do not grow forever.
There is, in theory, one place where a race is still possible, but it is not a dangerous one. The important file operations themselves are atomic, so the worst realistic outcome is something like last-write-wins, not a partially corrupted state. The actual overlap window is tiny, on the order of milliseconds. In practice this is more like minimal hygiene than a real systems problem. Do not sync your phone exactly at minute 00 or 30, and life goes on.
The inbox flow is split into a few hardcoded routes. Headlines tagged :task: go into task normalization and planning. Headlines tagged :link: go into URL capture for the knowledge base. And if a headline simply starts with http:// or https://, I also treat it as a link capture even without an explicit tag. Unknown headline types are skipped and logged instead of being handled magically.
The :task: flow is basically a two-stage pipeline.
The first stage is normalization. A raw mobile capture like call bookkeeper 2morrow ! is sent to an LLM with a fairly large system prompt that I wrote almost by hand.
(defconst sem-prompts-pass1-system-template
"You are a Task Management assistant. Your ONLY task is to transform a raw capture note into a valid Org-mode TODO entry.
%%CHEAT_SHEET%%
=== REQUIRED OUTPUT FORMAT ===
Your output MUST follow this exact structure:
* TODO <Cleaned Task Title>
:PROPERTIES:
:ID: <injected-id-value>
:FILETAGS: :<one-of:work:family:routine:opensource>:
:END:
<Normalized task notes; may be multi-line when input has meaningful multi-line context>
<Optional: SCHEDULED: <YYYY-MM-DD HH:MM-HH:MM>>
<Optional: DEADLINE: <YYYY-MM-DD Day>>
=== RULES ===
1. :FILETAGS: MUST be exactly one of: :work:, :family:, :routine:, or :opensource:
2. :ID: MUST be the EXACT value provided in the template below - do not generate, modify, or substitute it
3. Output ONLY the Org entry - no explanations, no markdown wrappers
4. Normalize the note into a concise, actionable TODO title and useful body text
5. CRITICAL: Preserve ALL <<SENSITIVE_N>> tokens VERBATIM in your output. These tokens represent masked sensitive content and must appear unchanged.
6. CRITICAL: Tokens must appear at the SAME semantic position as the original sensitive content appeared in the input.
7. If you include SCHEDULED, it must use time range format: SCHEDULED: <YYYY-MM-DD HH:MM-HH:MM>
8. If timing intent is ambiguous or low-confidence, it is valid to omit SCHEDULED
9. Prefer adding priority in headline token format [#A]/[#B]/[#C], but priority may be omitted when uncertain
10. Priority strength mapping: urgent/asap/critical/important!! -> [#A], soon/high -> [#B], routine/normal -> [#C]
=== RELATIVE TIME ANCHOR ===
Treat relative phrases against runtime context provided in user prompt as CURRENT DATETIME.
=== EXAMPLES (NORMALIZATION TARGETS) ===
- Input: \"2morrow send draft to team important!!\"
Output intent: cleaned title, [#A], schedule anchored to CURRENT DATETIME for tomorrow
- Input: \"next week sync with ops\"
Output intent: best-effort schedule only if confident; otherwise unscheduled TODO is valid
- Input: \"wendsday call vendor about invoice\"
Output intent: treat common misspelling as Wednesday when confidence is high; otherwise unscheduled
- Input: \"ASAP fix login bug but low urgency follow-up\"
Output intent: conflicting urgency resolves to strongest signal ([#A] > [#B] > [#C])
- Input: \"Call +1-800-555-0199 re INC-7781\"
Output intent: preserve identifiers and phone numbers verbatim in title/body
%%RULES%%
%%LANGUAGE%%"
"Template for Pass 1 system prompt.
Uses %%CHEAT_SHEET%%, %%RULES%%, and %%LANGUAGE%% as placeholders
that are substituted at runtime by sem-router.")The model is not asked to “help with tasks” in some vague sense. It is asked to output one valid Org TODO entry in a very strict format, with exact fields, exact :ID:, one allowed :FILETAGS: value, optional SCHEDULED, optional DEADLINE, headline priority in Org format, and no extra text. Relative time like 2morrow is resolved against the current runtime context and timezone, so it becomes a real date. Priority hints like !, important!!, asap, and similar signals are mapped into headline priorities such as [#A]. There is also a cheat sheet in the system prompt that explains Org syntax to the model and gives concrete normalization examples.
Then the deterministic side checks the result. I do not just trust the model because the output looks plausible. The generated entry is parsed and validated with org-element to make sure it is actually a valid TODO in the expected shape. If validation fails, there are retries. If retries fail, the item goes to the DLQ. This pattern appears in several places in the system: model output is proposed text, but Lisp is still the one deciding whether that text is structurally acceptable.
After all currently pending raw tasks are normalized and tracked through cursors into temporary files, the second stage starts: planning. Here I call a stronger model, but again inside a very constrained contract. The planner does not see my whole raw corpus. It gets a reduced, anonymized view of the already occupied schedule as interval-like structures with ids and tags, the tasks that still need scheduling, and a set of planning rules from rules.org.
Those rules are one of the main reasons I wanted my own system in the first place. They can say things like: on weekdays I work from 10 to 19, Saturday is family day, Sunday is shopping day, the local shop closes at 21:00, and anything marked “today” that requires shopping should be scheduled before that. This kind of behavior is deeply personal, slightly weird, and exactly the sort of thing that generic SaaS products usually cannot expose directly. If they let users freely inject such rules into the prompt layer, they would immediately create a large security and abuse surface for themselves. In my case this problem looks different, because rules.org is part of the trusted boundary. It lives next to the data, belongs to me, and can be passed into the system prompt directly. That gives me a level of behavioral control that would be very hard to get from a hosted product.
The planner returns a mapping from task ids to schedule assignments. Then Lisp assembles the final result in temporary files and atomically replaces tasks.org, which is effectively one of the user-facing UIs of the system.
The :link: flow is different. These entries are meant for the knowledge base. The system takes the URL, pulls readable article content through trafilatura, strips noise so tokens are not wasted on punctuation, HTML leftovers, and boilerplate, and then builds a new org-roam note. In my org-roam there are special umbrella nodes marked with the :umbrella: tag for larger themes such as Emacs, Python, Java, LLMs, and so on. The model receives the extracted text, the umbrella candidates, a pre-generated note id from Emacs, and a large system prompt. It then returns a new note that is expected to use that exact id and connect to the right umbrellas. Emacs does not trust this blindly either. The id is generated on the deterministic side, injected into the prompt, and then checked again in the model output. Even small details like this matter if one really treats the model as untrusted.
The same flow also has a very boring distribution mechanism, which I consider a good thing. Every six hours, newly created org-roam nodes are committed and pushed into a git repository. That push triggers a static site build from org-roam through GitHub Action, so I always have a fast browser version of my second brain on all devices. And on the laptop I just pull the same notes through git into Emacs. No special sync magic, just files and git again.

There is also a guardrail for sensitive information. The system supports a special #+begin_sensitive / #+end_sensitive block. Anything inside it is masked before the LLM call and replaced with placeholders like <<SENSITIVE_N>>. The model must preserve those placeholders and place them back in the correct semantic position. Only after that does Lisp restore the real contents. So I can keep things like passwords, keys, or account numbers in notes without sending them to the model, as long as I remember to wrap them. Any malformed sensitive block is treated as a hard error and goes straight to the DLQ.
The dead-letter queue is, naturally, also an Org file. Logs are written to an Org file as well. Error escalation works in the same spirit. Failures can be written into errors.org as overdue high-priority TODOs, for example with an already missed deadline and [#A]. Once the mobile client syncs, that naturally becomes a push notification on the phone. This means I do not need a separate push server at all. Less custom infrastructure means fewer moving parts, and fewer moving parts means fewer places where a vibecoded system can fail in embarrassing ways.
More generally, the whole implementation leans heavily on atomic replacement, defensive wrappers, retries, validation, and one golden rule: never let the daemon crash. I pushed the LLM quite hard to keep the code structured around outer condition-case blocks on public entry points and cron-callable functions, so that failures are caught, logged, and contained instead of tearing down the process. Even the logging paths are wrapped defensively and are not supposed to propagate errors further. I would much rather have one malformed item go into a DLQ, or one failure appear in errors.org, than have the whole server die because one model output was malformed. This is probably one of the most important design principles in the whole project. The LLM does useful local work, sometimes very useful local work, but it never becomes the thing that is trusted to hold the system together.
A part of the AGENTS.md file:
- Every public entry point and every cron-callable function must be wrapped in
`(condition-case err ... (error ...))`.
- Logging functions themselves are wrapped in `(ignore-errors ...)` or
`(condition-case _err ... (t nil))` — they must never propagate errors.
- Catch errors at the outermost layer; log with `sem-core-log-error`, then
continue. Do not re-signal.So, How Was It Built?
The short answer is: very iteratively, very spec-heavy, and with much more discipline than the phrase “vibecoded Emacs daemon” might suggest.
I relied heavily on OpenSpec and on the whole idea of iterative spec-driven development. OpenSpec itself describes this approach as lightweight, iterative, and built around agreeing on specs before code is written, precisely because AI coding assistants become unpredictable when requirements live only in chat history. In practice, this turned out to be one of the most useful ideas in the whole project.
Right now I have around 13,000 lines of Markdown specs for a project that contains only about 5,000 lines of Emacs Lisp code and another roughly 5,000 lines of tests. At the beginning this was honestly annoying. Writing endless specs feels much less fun than simply opening an agent and asking it to “build the thing” on vibes. But after maybe the tenth iteration, a very interesting effect started to appear.
In other words, the specs were not only memory for the model. They were also memory for me. This mattered much more than I expected. After enough iterations, I was no longer fully able to hold the whole system in my head, and the spec layer started acting as a kind of externalized project memory that could push back on both me and the agent.
I would come back with some new idea, ask the agent to implement X, and instead of obediently generating code, it would answer with something like: sorry, but in the spec you wrote earlier, event A must lead to behavior Y, and what you ask for now is behavior X. Either update the spec, or decide which requirement you want to keep. This feels almost magical the first time it happens. And to me it solves one of the main problems in AI-assisted development: how to keep specs readable enough for humans, while still preserving enough project memory that the model can push back when I contradict myself. OpenSpec was unexpectedly good at that.
The second major pillar was testing. I leaned heavily on integration tests written in Bash, and there I did much more manual inspection myself: preparing fixtures, checking outputs, looking at generated files, and deciding whether the behavior was actually correct. At this point these integration tests are probably the main support structure of the project, together with about 300 ert unit tests. The unit tests are useful mostly so that the next LLM iteration does not casually break what worked in the previous one. The integration tests are where I actually look at the system and ask: does this still behave like the software I wanted?
My main development loop was OpenCode with Codex 5.3. Periodically I would also point Claude Code with Opus 4.6 at the project, usually with a much harsher prompt along the lines of “audit this for security issues.” That kind of cross-model adversarial review turned out to be genuinely useful. One model would happily produce something plausible, another one would find a bad assumption, a weak boundary, or a failure mode I did not notice.
One unexpectedly useful trick was adding a tiny script to validate Lisp structure before wasting more time on deeper failures. It is basically a small Emacs batch script that scans files for unmatched brackets or quotes using scan-sexps.
#!/bin/bash
:;: '-*-emacs-lisp-*-'
:; exec emacs -Q --batch --load "$0" "$@"
(dolist (file command-line-args-left)
(with-temp-buffer
(insert-file-contents file)
(condition-case data
(scan-sexps (point-min) (point-max))
(scan-error (goto-char (nth 2 data))
(princ (format "%s:%s: error: Unmatched bracket or quote\n"
file
(line-number-at-pos)))))))This was needed because, for whatever reason, models seem especially talented at getting parentheses slightly wrong in Lisp. To be fair, this is also my own main pain point with Lisp :)

Before that script existed, there was a genuinely funny period when the agent would sometimes start manually “counting” parentheses in its reasoning, line by line, as if it had become a tired graduate student trapped inside an ert failure. The script was much more reliable.
More generally, the whole development process only worked because I kept forcing it into a shape where the model had less room to improvise. Specs were explicit. Boundaries were explicit. Contracts were explicit. The daemon should never crash. Sensitive blocks must never leak. Generated Org output must be structurally valid. IDs must match. Invalid output must retry and then go to DLQ. Once these constraints were written down clearly enough, AI coding became dramatically more useful.
So yes, this project was vibecoded. But not in the sense people often mean when they say that word. It was not “one vague prompt, one heroic agent, one glorious mess.” It was closer to iterative constrained development with a lot of specs, a lot of tests, and repeated adversarial checking. In my experience, this is where AI coding becomes genuinely powerful. Not when it replaces engineering, but when it makes a strange, narrow, deeply personal project realistic to finish.
Conclusion
So yes, in the end I really did build a personal automation system around Org files, LLMs, and headless Emacs in Docker Compose.
I am fully aware that this sounds slightly absurd. But I also think that, once one starts from the actual requirements instead of from fashionable stacks, it becomes much easier to justify. I wanted one system for notes, TODOs, planning, digests, and a second brain. I wanted LLMs inside it, but only in carefully bounded roles. I wanted plain text, privacy, inspectability, and as little vendor lock-in as possible. And once those constraints were fixed, the rest of the architecture followed much more naturally than I expected.
For me, this is also a story about something larger than Org or Emacs. What changed in the LLM era is not that software became magical, and not that autonomous agents suddenly became trustworthy. What changed is that building narrow, opinionated, deeply personal software became much more realistic. Not easy, not free, and definitely not automatic. But realistic.
I wanted software like this for a long time. Before LLM coding, I would almost certainly not have built it. Not because the idea was impossible, but because the implementation cost was simply too high for a strange one-user pet project that had to coexist with the rest of life. Five thousand lines of weird Emacs Lisp, thousands of lines of tests, and all the iteration around them is just not something I would have finished by hand.
This, to me, is one of the most interesting things happening right now. LLMs are often discussed in terms of startups, productivity gains, and replacing programmers. I think one much more interesting possibility is that they lower the cost of making software for oneself. Not software for a market. Not a generic framework. Not a “life OS” sold by subscription. Just software shaped around one person’s workflows, constraints, habits, and trust boundaries.
That is what this project is. It is weird, narrow, and probably useful to almost nobody except me. And I consider that a feature, not a bug.