Preface
I would like to thank Martin Grund. He gave me a lot of useful advice during my work on this project!
Introduction
Recently, I published a post about potential compatibility issues between SparkConnect and 3d-party libraries that depend on py4j. After that post, people from Databricks contacted me and suggested we work together on this issue. With their help, I tried to create a step-by-step guide for newbies on how to extend SparkConnect and how to potentially migrate from py4j logic to writing protocol plugins.
What is going on?
As you may know, Apache Spark 4.0 is coming. And it looks like the SparkConnect protocol will be the main way of communication between the driver and the user’s code. So we need to be ready for it. But there are still a lot of 3d party libraries based on Java/Scala core and PySpark bindings via py4j. There is also a gap in the Apache Spark documentation on how to extend the protocol, what are the best practices, and how to migrate your project to a new way of working.
What is Spark Connect
For anyone new to the topic, SparkConnect is a new modern way to make Apache Spark a little more “modular”. Instead of creating a Driver directly in the user’s code, we create a Driver in a remote SparkConnect server. All communication between the client and such a server is done via the gRPC protocol. This opens a lot of interesting possibilities, such as
- Easy creation of new language APIs, for example the recently introduced Go Spark Client;
- Better user isolation when working on shared clusters (like Databricks Shared Clusters);
- Reduced dependency hell because users do not have to check all Spark internal dependencies and only need a thin client;
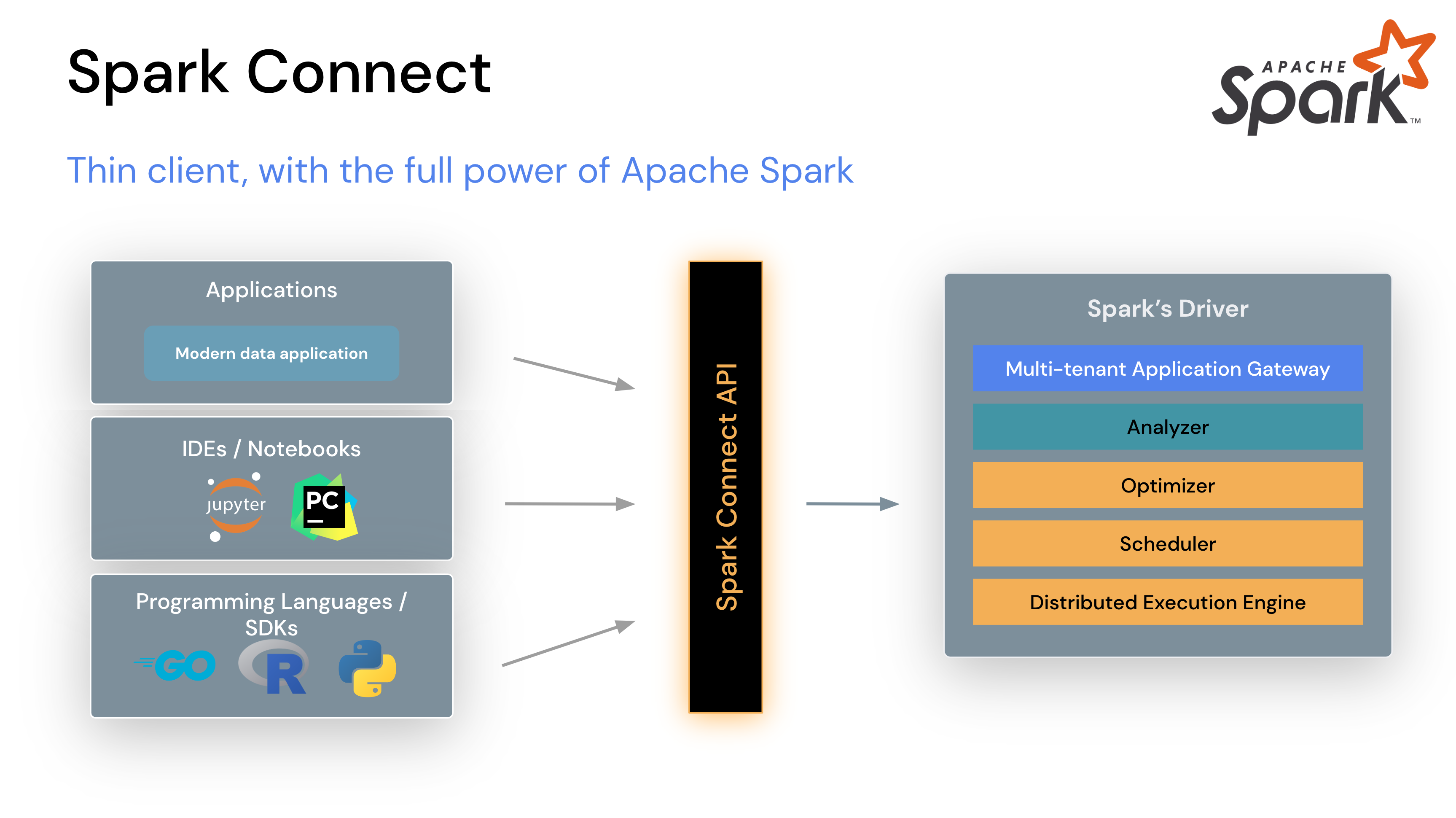
For a top-level overview, you can check out an Overview in Spark Documentation. For a deeper dive into the topic I recommend this nice blog post by Bartosz Konieczny or the video of Martin Grund’s presentation:
How the post is organized
- The first section will briefly describe how to get and configure everything you need to test a SparkConnect application. Like getting Spark itself, building it from source, fixing some bugs, etc. We will also touch on all the prerequisites needed to build an application:
Java,Maven,Python,protobuf,buf, etc; - After that, we will briefly touch on the basic structures provided by
Sparkfor extending the protocol:CommandPlugin,RelationPlugin,ExtensionPlugin; - Next, we will define the
JVMlibrary that we want to wrap in the SparkConnect extension; - After that, we will write all the necessary protocol extensions;
- The next step is to create a Python client;
- Finally, the end2end testing of the application;
- At the end I will try to say a few words about what is good in a new
SparkConnectand what is missing from my point of view.
Setup
In this project I will use Java instead of Scala. The reason is quite simple: in my understanding, any Scala dev can read Java code. But it does not always work well in the other direction just because of Scala magic and implicity. Of course, the same code will look more elegant in Scala, but since this is a blog post, readability should be the first priority. I will also use Maven as a build system, simply because Apache Spark itself uses this build tool.
Before we start, you will need the following
Java 17: Archive or install it through your system package manager or use SDKMan;Python 3.10: Archive or install it via the system package manager or use PyEnv;Maven: Download page or install it via the system package manager;Protobuf: Release Page, but it is better to install it via the system package manager;Buf: GitHub repo.
Build the latest Spark
The main reason to work directly with the latest Spark snapshot is that while the Spark Connect general implementation is readily available since Spark 3.4 for Python and Spark 3.5 for Scala, there is still a lot of work in progress to reduce sharp edges and improve documentation.
We need to work with a latest available spark-4.0.0-SNAPSHOT version. At first you need to clone it locally via git clone git@github.com:apache/spark.git. After that just go inside and call mvn ./build/mvn -Pconnect clean package. The next step is to generate corresponding PySpark library: cd python; python3.10 setup.py sdist. It will generate something like pyspark-4.0.0.dev0.tar.gz in dist folder. It is a ready to use distribution that may be installed into user’s environment.
A JVM library example
Our goal will be to try to wrap some existing Spark-Java logic that manipulates by instances of DataFrame class and also by own classes. Of course, at first, we need to define such a library first!
Command Logic
The simplest of all the possible cases is just a command. In the world of Spark Connect, a command is a simple way to invoke server-side logic that might incur a side-effect and does not necessarily return data. On the JVM-side it should be represented by public void command(A argA, B argB, ...). For example, it may be the case when we need to initialize library classes by something like public void init(). Another case is when we want to write something to the FileSystem. Let’s try to mimic such a case:
public class CommandLikeLogic {
public static void commandA(Long paramA, Long paramB, String paramC) throws IOException {
var spark = SparkSession.active();
var path = new Path(paramC);
var fs = path.getFileSystem(spark.hadoopConf());
var outputStream = fs.create(path);
outputStream.writeUTF(String.format("FieldA: %d\nFieldB: %d", paramA, paramB));
outputStream.flush();
outputStream.close();
}
}
It is a very dummy class with just a single method commandA(Long paramA, Long paramB, String paramC). It do the following:
- Get a current active
SparkSessionobject; - Get a right implementation of
org.apache.hadoop.fs.FileSystembased on the configuration from theSparkSession; - Write values of
paramAandparamBinto a file in path defined byparamC
As one may see there is no magic. But working with underlying org.apache.hadoop.fs.FileSystem is not possible from PySpark and it is very common case to write such a logic in JVM-languages!
DataFrame Logic
Another case is when JVM-object should create and return DataFrame (Dataset<Row>) object. It is the most common case for any kind of 3d-party library. From my experience developers typically work-around such a logic via py4j:
DataFrameinPySparkhas a private attribute_jdfthat representspy4j.java_gateway.JavaObjectcorresponds toDataset<Row>inJVM;DataFrameinPySaprkhas a constructor that takespy4j.java_gateway.JavaObjectandSparkSessionand returnspyspark.sql.DataFrame;
With SparkConnect this workaround doesn’t work anymore, so let’s see how we may do it in a new and right way. Let’s try to wrap the following simple class:
public class DataFrameLogic {
public static Dataset<Row> createDummyDataFrame() {
var schema =
new StructType(
new StructField[] {
DataTypes.createStructField("col1", DataTypes.LongType, true),
DataTypes.createStructField("col2", DataTypes.StringType, true),
DataTypes.createStructField("col3", DataTypes.BooleanType, true)
});
var spark = SparkSession.active();
var rows = new ArrayList<Row>();
var gen = new Random();
for (int i = 0; i <= 10; i++) {
rows.add(
RowFactory.create(
gen.nextLong(),
String.format("%d-%d", gen.nextInt(), gen.nextLong()),
gen.nextBoolean()));
}
return spark.createDataFrame(rows, schema);
}
}
As one may see it is a really dummy object. And, of course, you can do exactly the same in pure PySpark (doesn’t matter, with SparkConnect or not). But let’s still try to wrap it just to understand how it works. In this case this simple class should be enough for our purposes. In the world of Spark Connect, this DataFrame logic is represented by Relation messages. These messages are declarative transformations that can be arbitrarily nested and are very similar to the standard Spark SQL operations like project, filter, groupBy.
Manipulation of JVM objects
The most complex and tricky thing is when we need not only call void commands or create/modify DataFrame objects, but create instances of regular JVM classes and calls methods of them. To mimic such a case let’s again create a dummy Java class with couple of getter/setter methods, constructor and, for example, custom toString() implementation:
public class ObjectManipulationLogic {
private String strParameter;
private Long longParameter;
public ObjectManipulationLogic(String strParameter, Long longParameter) {
this.strParameter = strParameter;
this.longParameter = longParameter;
}
public String getStrParameter() {
return strParameter;
}
public void setStrParameter(String strParameter) {
this.strParameter = strParameter;
}
public Long getLongParameter() {
return longParameter;
}
public void setLongParameter(Long longParameter) {
this.longParameter = longParameter;
}
@Override
public String toString() {
return "ObjectManipulationLogic{"
+ "strParameter='"
+ strParameter
+ '\''
+ ", longParameter="
+ longParameter
+ '}';
}
}
Our class has a public constructor just for simplicity. In reality, of course, it could be more complex with factory methods. But it should be enough for our demo case.
Our class has two fields, corresponding getters/setters, and a custom `toString’. In reality, of course, no one will wrap complex JVM logic in SparkConnect. But as you will see in the next sections, there is no fundamental difference in which method is called. So such a class is complex enough for our demo purposes.
Defining protobuf messages
At first, to start any kind of SparkConnect extending we need to define contracts in the form of protobuf messages that are interpreted by Spark. We decided to use the following three use-cases:
- Calling a command;
- Creating a
DataFrame; - Manipulating
JVMobject.
syntax = 'proto3';
option java_multiple_files = true;
option java_package = "com.ssinchenko.example.proto";
message CallCommandLikeLogic {
int64 paramA = 1;
int64 paramB = 2;
string paramC = 3;
}
message CallDataFrameLogic {}
message CallObjectManipulationLogic {
int32 objectId = 1;
bool newObject = 2;
bool deleteObject = 3;
string methodName = 4;
repeated string args = 5;
}
Let’s go step by step.
The first rows tells us to use proto3 (protobuf version 3) syntax, which package is it, which java package is it, etc. There is no special magic, so, just use it as an example for your Spark proto code.
message CallCommandLikeLogic {
int64 paramA = 1;
int64 paramB = 2;
string paramC = 3;
}
This message will be used to call a CommandLikeLogic Java class. As you remember, the only static method commandA takes exactly three arguments (Long paramA, Long paramB, String paramC). In protobuf syntax it transforms into int64 paramA, int64 paramB and string paramC. Numbers in proto-syntax means the id of argument in the message, you can read more about it in the protobuf documentation.
The message for CallDataFrameLogic is even simpler: it is just an empty one, but we still need it for checking the appropriate command.
The last message is quite tricky. To manipulate objects in JVM via gRPC we need at least the following:
- An ID of the object just to know which one should we touch in
JVM; - A flag that we need to create a new object instead of manipulating existing one;
- A flag that we need to delete an existing object;
- A name of the method we want to call (in the case when we do not want to delete or create an object);
- A list of strings-represented arguments;
And it gain us the structure of the CallObjectManipulationLogic message:
message CallObjectManipulationLogic {
int32 objectId = 1;
bool newObject = 2;
bool deleteObject = 3;
string methodName = 4;
repeated string args = 5;
}
Because in proto3 syntax any argument is optional we do not need to mark fields as optional or required. So, all the checking logic is moving to runtime.
Generating Classes and Methods from proto-code
Now we need to generate corresponding Java classes and methods based on the proto3 code. Of course you can use something like protoc -I=... -java_out=... .... But it is not the simplest way. To make it simpler there is a very cool tool named buf (link to the buf repo in GitHub). I already mentioned this tool in previous sections. With buf generation for all the languages may be done via one command: buf generate. But at first we need to define buf.work.yaml and buf.gen.yaml that should contain the information about which plugins we want to use.
buf.work.yaml:
version: v1
directories:
- protobuf
buf.gen.yaml:
version: v1
plugins:
- plugin: buf.build/protocolbuffers/python:v25.3
out: python/spark_connect_example/proto
- plugin: buf.build/grpc/python:v1.62.0
out: python/spark_connect_example/proto
- plugin: buf.build/community/nipunn1313-mypy:v3.5.0
out: python/spark_connect_example/proto
- plugin: buf.build/protocolbuffers/java:v25.3
out: java
NOTE: You may find a list of available
bufplugins here.
The first one defines the protobuf files directory, the second one defines what should be generated and also where this files should be places. Let’s again see on the structure of the project to better understand what’s going on:
|- src
|-- main
|--- java
|---- com/ssinchenko/example
|----- lib
|----- proto # <- generated from proto Java classes will be here
|----- server
|--- protobuf # <- proto3 code is here
|--- python
|---- spark_connect_example
|----- proto # <- generated from proto Python classes will be here
|---- pyproject.toml
|--- buf.gen.yaml
|--- buf.work.yaml
|- pom.xml
So, long story short, all that you need from now to generate (or regenerate) all the classes/py-files is to call buf generate from the src/main directory.
CommandPlugin
As I mention already, the case of void command is the simplest one. Let’s see how implementation of the CommandPlugin will look for the case of our CommandLikeLogic class:
public class CommandLikeLogicPlugin implements CommandPlugin {
@Override
public boolean process(byte[] command, SparkConnectPlanner planner) {
Any commandProto;
try {
commandProto = Any.parseFrom(command);
} catch (InvalidProtocolBufferException e) {
throw new RuntimeException(e);
}
if (commandProto.is(CallCommandLikeLogic.class)) {
try {
var message = commandProto.unpack(CallCommandLikeLogic.class);
CommandLikeLogic.commandA(message.getParamA(), message.getParamB(), message.getParamC());
} catch (IOException e) {
return false;
}
}
return true;
}
}
NOTE: In this case
CallCommandLikeLogicis exactly the generated bybufclass. It contains more than 500 lines of Java code, so I cannot put it here. But you may generate your own to see how it looks like!
Let’s in details on the syntax.
implements CommandPluginis just about which interface should we implement;- we always gets
byte[]as an input; you may check it the spark source code; Anyin this case not just any class, butproto.Any: link to rest API documentation;planneris a spark internal tool that contains a lot of useful things, includingSparkSessionitself:var = planner.sessionHolder().session();;command.is(...)verifies that the embedded message types is of the class we expect;command.unpack(...)unpack the command into an actual generated Class with methods;- finally we just call our method from out JVM “library” like class.
RelationPlugin
A more tricky case is when we need to return DataFrame. For that case we need to implement RelationPlugin. It requires to override a method transform:
public class DataFrameLogicPlugin implements RelationPlugin {
@Override
public Optional<LogicalPlan> transform(byte[] relation, SparkConnectPlanner planner) {
Any relationProto;
try {
relationProto = Any.parseFrom(relation);
} catch (InvalidProtocolBufferException e) {
throw new RuntimeException(e);
}
if (relationProto.is(CallDataFrameLogic.class)) {
return Optional.of(DataFrameLogic.createDummyDataFrame().logicalPlan());
}
return Optional.empty();
}
}
As one may see it is quite similar to command but instead of boolean we need to return an Optional<LogicalPlan>. On the JVM side you can easily get this plan by just calling df.logicalPlan() and that’s it.
NOTE: You only need to return
Optional.emptyif the command is not for this handler! In all other cases you must either throw an exception or return an actualLogicalPlan!
Objects Manipulation
The most advanced case is when we want to manipulate an object on the JVM side, as it can be done before with py4j. It is a little tricky because we can only use LogicalPlan for interaction between JVM and client! To implement this thing I will use the following:
- I will use
HashMap<Integer, Object>to map all objects to integer IDs; - To generate an ID of the object I will use
System.identifyHashCode(obj); - All communication with the client will be done via
LogicalPlan, even error messages can be transported this way; - Inside I will parse an input message and call create, delete object or call methods;
To simplify things, I based my code on the assumption that there may be only 100 objects, or that arguments passed by the client are always correct. And of course I have not touched the topic of ID collision. But you can extend this code to achieve all of the above. My goal was just to create a kind of proof of concept, nothing more!
public class ObjectManipulationLogicPlugin implements RelationPlugin {
/** This is a map, that stores link to all the objects. */
private static final HashMap<Integer, ObjectManipulationLogic> idsMapping = new HashMap<>(100);
public static ObjectManipulationLogic getObj(Integer id) {
return idsMapping.get(id);
}
public static Integer addObj(ObjectManipulationLogic obj) {
var id = System.identityHashCode(obj);
idsMapping.put(id, obj);
return id;
}
public static void update(Integer id, ObjectManipulationLogic obj) {
idsMapping.put(id, obj);
}
public static void dropObj(Integer id) {
idsMapping.remove(id);
}
private Dataset<Row> getSuccessDF(SparkSession spark) {
return spark.createDataFrame(
List.of(RowFactory.create("success")),
new StructType(
new StructField[] {
DataTypes.createStructField("status", DataTypes.StringType, false)
}));
}
@Override
public Optional<LogicalPlan> transform(byte[] relation, SparkConnectPlanner planner) {
// To make the code simpler I'm not checking type of passed from Python arguments!
// So, the overall logic is build on the assumption, that it is impossible to get
// from python an invalid string or invalid long.
//
// It makes sense, because it is x10 simpler to do it on the Python side
Any relationProto;
try {
relationProto = Any.parseFrom(relation);
} catch (InvalidProtocolBufferException e) {
throw new RuntimeException(e);
}
if (relationProto.is(CallObjectManipulationLogic.class)) {
var spark = planner.sessionHolder().session();
try {
// We are parsing the message
var message = relationProto.unpack(CallObjectManipulationLogic.class);
if (message.getNewObject()) {
// If we need to create a new object we are doing the following:
// 1. Get args
// 2. Create an instance
// 3. Add an id of the instance to the Map
// 4. Return the id to Python
var args = message.getArgsList();
var paramA = args.get(0);
var paramB = Long.parseLong(args.get(1));
var instance = new ObjectManipulationLogic(paramA, paramB);
var id = ObjectManipulationLogicPlugin.addObj(instance);
var df =
spark.createDataFrame(
List.of(RowFactory.create(id)),
new StructType(
new StructField[] {
DataTypes.createStructField("id", DataTypes.IntegerType, false)
}));
return Optional.of(df.logicalPlan());
} else if (message.getDeleteObject()) {
// If we need to drop the object we just delete it from the Map
// After that GC will do it's work.
var id = message.getObjectId();
ObjectManipulationLogicPlugin.dropObj(id);
return Optional.empty();
} else {
// All other cases is when we need to call a method
var methodName = message.getMethodName();
var args = message.getArgsList();
var id = message.getObjectId();
var instance = ObjectManipulationLogicPlugin.getObj(id);
// Possible to do the same via Reflection API;
// But to achieve explicitly I'm directly check the method name.
// We need to know types anyway, to return a DataFrame with a right schema.
// So, we are checking all the possible methods and do the following:
// 1. If it is setter than just parse args and modify the obj
// 2. If it is getter or toString we just wrap the output into DataFrame
switch (methodName) {
case "getStrParameter" -> {
var df =
spark.createDataFrame(
List.of(RowFactory.create(instance.getStrParameter())),
new StructType(
new StructField[] {
DataTypes.createStructField("strParameter", DataTypes.StringType, false)
}));
return Optional.of(df.logicalPlan());
}
case "getLongParameter" -> {
var df =
spark.createDataFrame(
List.of(RowFactory.create(instance.getLongParameter())),
new StructType(
new StructField[] {
DataTypes.createStructField("longParameter", DataTypes.LongType, false)
}));
return Optional.of(df.logicalPlan());
}
case "setStrParameter" -> {
instance.setStrParameter(args.get(0));
update(id, instance);
return Optional.of(getSuccessDF(spark).logicalPlan());
}
case "setLongParameter" -> {
instance.setLongParameter(Long.parseLong(args.get(0)));
update(id, instance);
return Optional.of(getSuccessDF(spark).logicalPlan());
}
case "toString" -> {
var df =
spark.createDataFrame(
List.of(RowFactory.create(instance.toString())),
new StructType(
new StructField[] {
DataTypes.createStructField(
"stringRepresentation", DataTypes.StringType, false)
}));
return Optional.of(df.logicalPlan());
}
default -> {
var df =
spark.createDataFrame(
List.of(
RowFactory.create(String.format("Invalid method name %s", methodName))),
new StructType(
new StructField[] {
DataTypes.createStructField("errorMessage", DataTypes.StringType, false)
}));
return Optional.of(df.logicalPlan());
}
}
}
} catch (IOException e) {
// In the case of error we are just wrapping the error message to DataFrame
var sw = new StringWriter();
var pw = new PrintWriter(sw);
e.printStackTrace(pw);
var df =
spark.createDataFrame(
List.of(RowFactory.create(String.format("IOException %s", sw))),
new StructType(
new StructField[] {
DataTypes.createStructField("errorMessage", DataTypes.StringType, false)
}));
return Optional.of(df.logicalPlan());
}
}
// That is the case when the message corresponds to another plugin/extension.
return Optional.empty();
}
}
Build the project
To build the project it is enough just to call mvn clean package and it will create an artifcat like this connect-1.0-SNAPSHOT.jar. Of course, in assumption, that you are using the code of my example from GitHub repository!
SparkConnect Plugins in Python
To setup all the dependencies do the following:
- Make
SPARK_HOMEvariable points to the place where gou clonedspark. In my case it isexport SPARK_HOME=~/github/spark; - In you python project (in my repo it is
src/main/python) create virtual environment:python3.10 -m venv .venv; - Install pyspark dependencies:
source .venv/bin/activate && pip install -r ${SPARK_HOME}/dev/requirements.txt; - Install pyspark itself:
source .venv/bin/activate && pip install ${SPARK_HOME}/python/dist/pyspark-4.0.0.dev0.tar.gz.
It should be enough to run my example and to make autocomplete works.
Implementation in Python
If you did not generate needed python-classes that implements protobuf Messages, you can easily do it via buf generate (from src/main).
The next step is to implement a gRPC client.
CallCommand
Each message kind should be implemented as a separate Python class that inherit from pyspark.sql.connect.plan.LogicalPlan. For command you need to override the command method:
class CallCommandPlan(LogicalPlan):
def __init__(self, param_a: int, param_b: int, param_c: str) -> None:
super().__init__(None)
self._a = param_a
self._b = param_b
self._c = param_c
def command(self, session: SparkConnectClient) -> proto.Command:
command = proto.Command()
command.extension.Pack(CallCommandLikeLogic(paramA=self._a, paramB=self._b, paramC=self._c))
return command
And after that you can create a function that uses this class. Remember that even if it is just a Command, you still need to call an action on the returned DataFrame!
def call_command(a: int, b: int, file_name: str, spark: SparkSession) -> None:
print(file_name)
DataFrame(CallCommandPlan(a, b, file_name), spark).collect()
CallDataFrame
The next in a row is a dummy function that generates DataFrame:
class CallDataFrameLogicPlan(LogicalPlan):
def __init__(self) -> None:
super().__init__(None)
def plan(self, session: SparkConnectClient) -> proto.Relation:
plan = self._create_proto_relation()
ext = CallDataFrameLogic()
plan.extension.Pack(ext)
return plan
def create_dataframe_extension(spark: SparkSession) -> DataFrame:
return DataFrame(CallDataFrameLogicPlan(), spark)
Almost like a Command but now you need to override plan method, not command.
Objects Manipulation
The most tricky part. As you remember, we used IDs in JVM side to provide a way of interacting between client and java-object. But before we implement a Python wrapper on top of Java object we need to create a LogicalPlan extension:
class CallObjectManipulationPlan(LogicalPlan):
def __init__(
self,
object_id: int = 0,
new_object: bool = False,
delete_object: bool = False,
method_name: str = "",
jargs: list[str] | None = None,
) -> None:
if jargs is None:
jargs = []
super().__init__(None)
self._object_id = object_id
self._new_object = new_object
self._delete_object = delete_object
self._method_name = method_name
self._jargs = jargs
def plan(self, session: SparkConnectClient) -> proto.Relation:
plan = self._create_proto_relation()
ext = CallObjectManipulationLogic(
objectId=self._object_id,
newObject=self._new_object,
deleteObject=self._delete_object,
methodName=self._method_name,
args=self._jargs,
)
plan.extension.Pack(ext)
return plan
This class is very similar to our dummy CallDataFrameLogicPlan but not we have an actual constructor with fields.
Let’s see, how the Python class corresponds to the Java class may be written:
class JavaLikeObject:
def __init__(self, param_a: str, param_b: int, spark: SparkSession) -> None:
query_plan = CallObjectManipulationPlan(
new_object=True, jargs=[param_a, str(param_b)]
)
df = DataFrame(query_plan, spark)
if "errorMessage" in df.columns:
err_msg = df.collect()[0].asDict().get("errorMessage", "")
raise ValueError(err_msg)
obj_id = df.collect()[0].asDict().get("id", -1)
self._id = obj_id
self._spark = spark
def get_str_parameter(self) -> str:
query_plan = CallObjectManipulationPlan(
object_id=self._id, method_name="getStrParameter"
)
return (
DataFrame(query_plan, self._spark)
.collect()[0]
.asDict()
.get("strParameter", "")
)
def get_long_parameter(self) -> int:
query_plan = CallObjectManipulationPlan(
object_id=self._id, method_name="getLongParameter"
)
return (
DataFrame(query_plan, self._spark)
.collect()[0]
.asDict()
.get("longParameter", -1)
)
def set_str_parameter(self, str_par: str) -> None:
query_plan = CallObjectManipulationPlan(
object_id=self._id, method_name="setStrParameter", jargs=[str_par]
)
DataFrame(query_plan, self._spark).collect()
def set_long_parameter(self, long_par: int) -> None:
query_plan = CallObjectManipulationPlan(
object_id=self._id,
method_name="setLongParameter",
jargs=[str(long_par)],
)
DataFrame(query_plan, self._spark).collect()
def to_string(self) -> str:
query_plan = CallObjectManipulationPlan(
object_id=self._id, method_name="toString"
)
return (
DataFrame(query_plan, self._spark)
.collect()[0]
.asDict()
.get("stringRepresentation", "")
)
def delete(self) -> None:
query_plan = CallObjectManipulationPlan(
object_id=self._id, delete_object=True
)
DataFrame(query_plan, self._spark)
Here we just cover each of possible method in Java in the corresponding Python method.
End2end demo
Let’s check the most interesting part: objects manipulation. To do we need to create a main.py file:
from pyspark.sql.connect.session import SparkSession
from spark_connect_example.app_plugin import JavaLikeObject
if __name__ == "__main__":
spark = SparkSession.builder.remote("sc://localhost:15002").getOrCreate()
# Creating an object
java_like = JavaLikeObject(param_a="some", param_b=100, spark=spark)
# Call setter
java_like.set_str_parameter("some")
# Call setter
java_like.set_long_parameter(1)
# Call getter
print(java_like.get_long_parameter())
# Call setter again
java_like.set_long_parameter(2)
# Check that getter returns a new value
print(java_like.get_long_parameter())
# Call toString
print(java_like.to_string())
Running SparkConnect server
Now we need to do some manipulations in the folder where we cloned spark. For me it was ~/github/spark. Or just do something like cd $SPARK_HOME.
Before we can actually check this, we need to have the SparkConnect server up and running. For some unknown reason, a recommended way to build Spark with connect support did not add the Java protobuf library to CP. To fix this, I just got it from Maven Central: wget https://repo1.maven.org/maven2/com/google/protobuf/protobuf-java/3.22.0/protobuf-java-3.22.0.jar.
We also need to copy the built connect-1.0-SNAPSHOT.jar into the same folder as spark. Finally, we need to execute a very long command, so it is better to create a short bash script for it:
./sbin/start-connect-server.sh \
--wait \
--verbose \
--jars connect-1.0-SNAPSHOT.jar,protobuf-java-3.22.0.jar \
--conf spark.connect.extensions.command.classes=com.ssinchenko.example.server.CommandLikeLogicPlugin \
--conf spark.connect.extensions.relation.classes=com.ssinchenko.example.server.DataFrameLogicPlugin,com.ssinchenko.example.server.ObjectManipulationLogicPlugin \
--packages org.apache.spark:spark-connect_2.13:4.0.0-SNAPSHOT
Let’s see it in details:
--waitmeans to wait for the process to exit. OtherwiseSparkConnectwill run in background;--verbosejust add some additional debug information;--jars: we need to pass here ourconnect-1.0-SNAPSHOT.jar. In my case it was necessary to pass alsoprotobuf-java;--conf spark.connect.extensions.relation.classes=...: we should mention here all the plugins for relations;--conf spark.connect.extensions.relation.classes: the same, but for commands;--packages org.apache.spark:spark-connect_2.13:4.0.0-SNAPSHOT: just tell spark what to run.
To run the server, just run the bash script we just made. Another way is to copy this long command into you terminal.
Running an application
After running the server, just go back to our src/main/python and run the command source .venv/bin/activate && python main.py. You will see something like:
1
2
ObjectManipulationLogic{strParameter='some', longParameter=2}
NOTE: To see detailed logs from python side, use
export SPARK_CONNECT_LOG_LEVEL=debug
Anyway, as you can see, our workaround to call JVM from PySpark-connect thin client works!
🥳🥳🥳🥳🥳🥳🥳🥳
Discussion
What was cool?
I found that having a built-in way to serialize and deserialize LogicalPlan is very cool! It opens up a lot of possibilities for what you can do with SparkConnect! By packing everything into DataFrame and unpacking it on the client side, you can pass almost anything. I guess you could even serialize code into binary format and pack it into DataFrame. Of course, this might look a little crazy, but no more crazy than the magic of py4j!
What seems to be missing
Test environment
There is no easy way to test your application against SparkConnect. You always have to get binaries, and that is not cool. Even if you need to work with the 3.5.x version, you always have to download both binaries and PySpark, which means you download all jar files twice. It would be very cool if we had a simpler way.
Error messages
Error messages from SparkConnect are still sometimes not informative enough. For example, you might get something like org.apache.spark.sql.connect.common.InvalidPlanInput: No handler found for extension and it is not at all obvious what the reason is and on which message it happened. Is the problem in the Java plugin implementation? Or maybe there is a problem in the Python serialization? Or is it just a missing plugin class in CP? Unfortunately, you have to check all these cases, because the error message says almost nothing.
Afterword
I hope my example will help you in your research and development!
P.S. If you find this guide useful, it is not necessary to buy me coffee or anything like that. Just go and star the corresponding repository in Git to show me that all my efforts were not in vain!