Generating Python docstrings with GPT and Emacs
Motivation
There is an open source library in which I'm a maintainer. And recently I committed to creating docstrings for all the public functions and methods. I heard that recent Large Language Models (LLM) are good enough in the annotation of texts and documenting of code so I decided to try to use one of OpenAI models to solve this problem. In this post I will use Emacs plugins and extensions to generate docstrings but most advises about which prompt is better to use are generic and may be used with different code editors and IDE's.
Setup Eamcs and GPT
If you are not a user of
Emacseditor you can skip this block completely.Similar plugins may be found for almost all the editors:
Creating OpenAI account
First, you must create an OpenAI account. You can do it on their website. You also need an API Token which you can generate in Personal -> Manage account -> API keys -> +Create new secret token.
Configure Eamcs
There is already an Emacs OpenAI organization that provide a low-level library openai and also a high-level interface codegpt. To provide API keys to the library add the following lines to your Emacs config file:
(require 'openai)
(setq openai-key "sk-*************************************")
(setq openai-user "user")
(setq openai--show-log t)So all that you need to do is to install these libraries.
Choose a right prompt
It may be important that by default
codegptlibrary usestemperature=1.0. I tried also to usetemperature=0.0but it changed nothing.
By default codegpt library provide the function for generating documentation to any code:
;;;###autoload
(defun codegpt-doc (start end)
"Automatically write documentation for your code.
This command is interactive region only, the START and END are boundaries of
that region in buffer."
(interactive "r")
(codegpt--internal
"Please write the documentation for the following function."
start end))But this function is designed to generate documentation for any language. The problem with Python is it has three popular formats for generating docstrings: Google, NumPy, and Sphinx (or ReStructuredText). And the library for which I was trying to generate docstrings used sphinx format. So I created my own function to do it:
;; CodeGPT custom prompts
(defun codegpt-pysphinx (start end)
(interactive "r")
(codegpt--internal
"Please write the reStructuredText documentation for the following Python function in reStructuredText format."
start end))It is highly recommended to add as much as possible mentions of desired docstrings format. As you will see later even doubled directives to provide reStructuredText style docstrings are not enough and sometimes GPT returns something strange…
Docstring for a simple function
Let's try our approach on a very simple one-line function using text-davinchi-003 LLM:
Please write the reStructuredText documentation for the following Python function as a docstring in sphinx format.
def column_to_list(df: DataFrame, col_name: str) -> List[Any]:
return [x[col_name] for x in df.select(col_name).collect()]
"""
column_to_list
This functions takes a DataFrame and a column name as argument and returns a
list of elements corresponding to the values in the column.
:param df: A DataFrame.
:type df: `DataFrame`
:param col_name: Name of the column to be processed.
:type col_name: `str`
:return: List of elements.
:rtype: `List[Any]`
.. note::
This is an example of reStructuredText (reST) syntax.
"""Here we have a good docstring but with a couple of problems:
- additional line on the top;
- a very-very strange
notewhich is also not supported byMKDocsgenerator; - typo: functionS instead of function.
But it can be easily done by just copying only required part of the text and fixing typos. The most important is that LLM recognize the context right and generate an exact description what this function is really do.
Docstring for a big function
For big complex functions, it works even worse. The first couple of tries returns me a picture like this one:
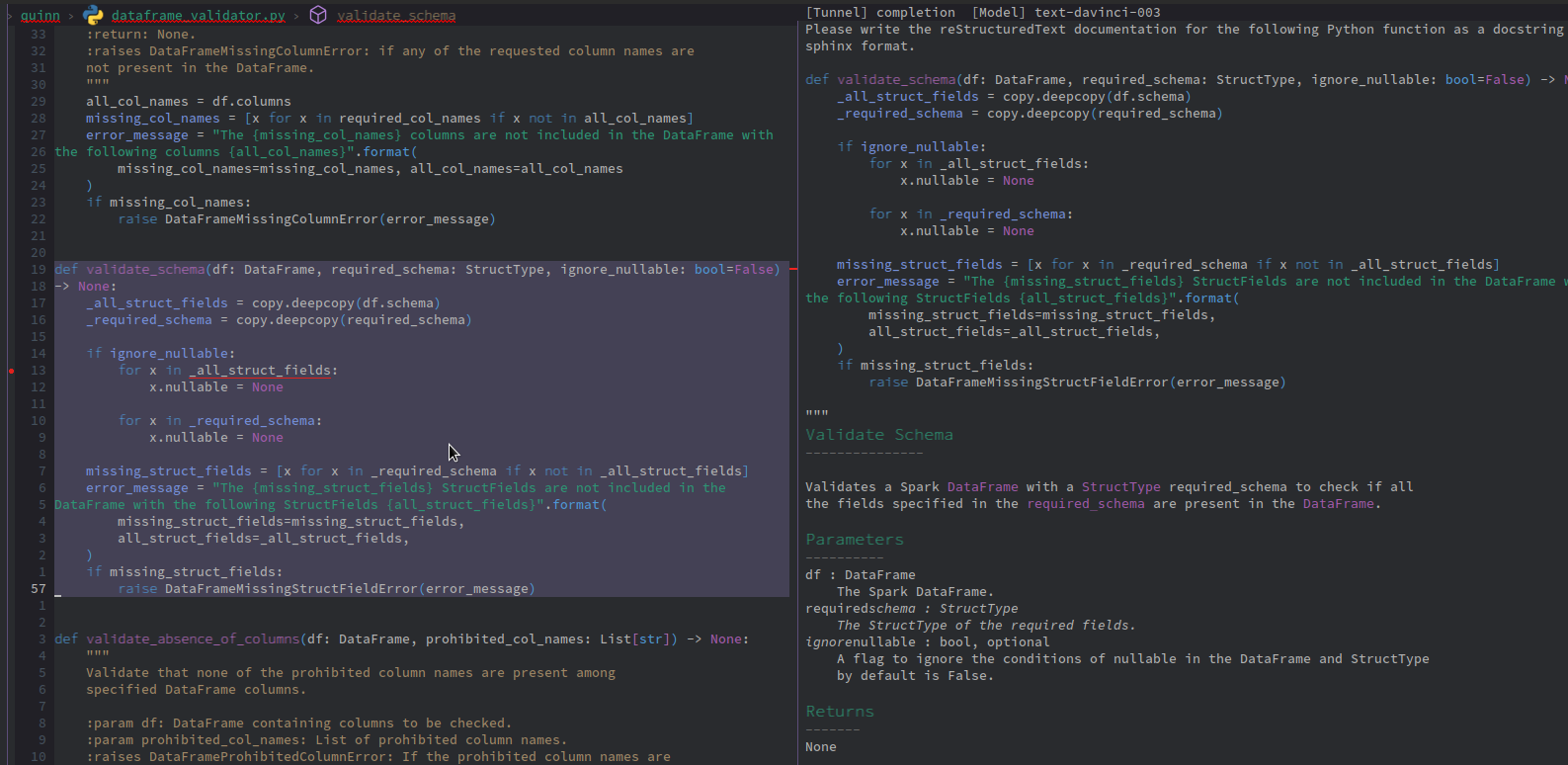
So even two explicit directives to use reStructuredText and sphinx are not enough sometimes.
After some retries with absolutely the same query I finally got what I desired:
"""
:param df: A :class:`~pyspark.sql.DataFrame` object to validate the schema against
:param required_schema: A :class:`~pyspark.sql.types.StructType` expected schema to
validate
:type required_schema: StructType
:param ignore_nullable: A boolean to determine if the nullable property should be
ignored when validating
:type ignore_nullable: bool, optional
:returns: None
Validate a DataFrame against required schema structure.
This function will copy both the current DataFrame schema and the required
schema structure and compare
if the DataFrame schema contains all the expected fields of the required schema
structure.
If one of the fields is not found, a DataFrameMissingStructFieldError will be
raised.
If ignore_nullable is set to True, the function will ignor the nullable property
of the two schemas
for validation.
"""There are some problems like a wrong order of parameters and description blocks or using of :class: tag which is not supported by MKDocs. But all of these can be easily fixed.
Some funny things
Sometimes LLM started to dream out of the blue. For example once it returns me docstrings with notes about changes in interface. The most interesting thing is that such a changelog looked very believable, despite being fictional from start to finish!
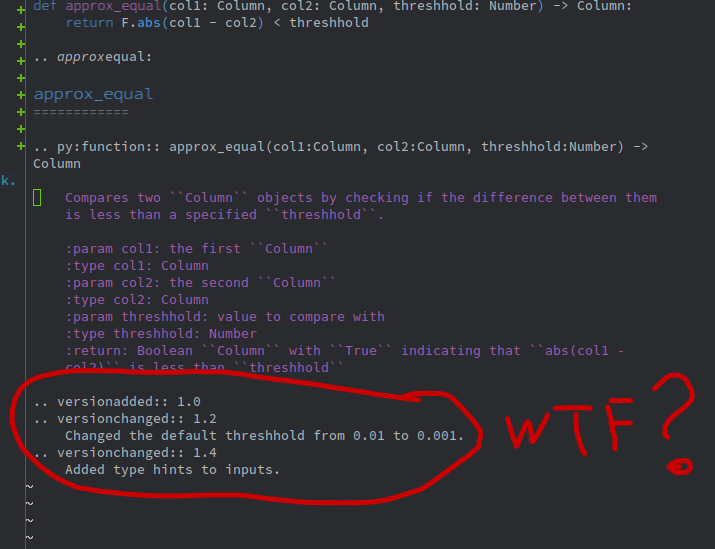
Conclusion
LLM looks very promising in such a common task like as generating documentation for the existing code. But even simple docs requires a careful control from the human side. Anyway I will use it in my projects because it is significantly better than write documentation from scratch by yourself. I do not think that LLV models can replace software developers in the nearest feature but I think that they will change the whole process of development and will become as much an integral part of development as, for example, IDEs have become.
P.S. I spend about 0.20 USD on LLM calls and about 30 minutes to setup all the configuration and generate all the docstrings. I'm absolutely sure that manual generation of docs would require significantly bigger amount of time!