TLDR;
This is a toy benchmark, not a paper, not a Spark benchmark, and not a “Java beats native” victory lap.
I implemented simple arithmetic kernels like addInt32 and mulFloat64 in 100% Java over Apache Arrow buffers, using MemorySegment and the JDK Vector API. No JNI, no native extension, no Unsafe, no sidecar process. Then I compared them with a native Apache Arrow reference implementation (production grade library). The result was boring in the interesting way: same class of performance, sometimes Java slightly ahead in my local runs, sometimes native is slightly ahead. The bottlenecks were exactly what you would expect: memory layout, CPU cache, RAM bandwidth, and hardware.
That is why the phrase "JVM tax" annoys me.
- If you mean Spark scheduler overhead, say Spark tax.
- If you mean shuffle, say shuffle tax.
- If you mean object graphs and GC-visible data, say object layout tax or GC tax.
But if the claim is that a warmed-up JVM cannot run analytical kernels efficiently over modern columnar memory, then show me where that tax is collected. Same buffers. Same semantics. Same hardware. Where is the JVM tax?
Disclaimer
This is not a paper.
I am not trying to prove that Java is faster than native code. I am not trying to prove that Spark is fast. I am not trying to rewrite arrow-compute in Java just to win an internet argument. I wrote a small toy project, implemented a few simple kernels, ran JMH on my laptop, and compared the results with a native Arrow reference implementation used in the most straightforward way I could find.
The Java code is most probably not optimal being 100% vibe-coded. The native side is probably not optimal either. I did not spend a week staring at JFR, or trying to overfit every last benchmark parameter. And honestly, I do not care that much about the last 3%.
What I care about is the order of magnitude of the alleged JVM tax. If the tax is supposed to be a serious reason to rewrite Big Data systems away from the JVM, I would expect it to show up as something more interesting than benchmark noise, cache effects, memory bandwidth, and normal implementation details. The code is public. Clone it, run it, break it, improve it, complain about it. That is more useful than another vague comment about "JVM tax".
Introduction: the phrase that annoyed me
Every second post about rewriting Big Data systems in native code has some version of this sentence:
Stop paying the JVM tax.
And every time I see it, I have the same question:
Which tax exactly?
Because very often "JVM tax" is used as a lazy bucket for everything people dislike about old Big Data systems.
Spark has real overheads. A lot of them. It has a distributed scheduler. It has shuffle. It has spill. It has stage boundaries. It has task overhead. It has fault tolerance machinery. It has old APIs. It has row-oriented paths. It has blocking execution patterns. It has a shuffle model that was designed for a very different era of hardware and storage. It has a lot of architecture that predates the current fashion of tight columnar/vectorized engines inspired by things like MonetDB/X100.
All of that is real. But why is that called JVM tax?
- If you mean Spark tax, say Spark tax.
- If you mean shuffle tax, say shuffle tax.
- If you mean scheduler tax, say scheduler tax.
- If you mean row-oriented execution tax, say row-oriented execution tax.
- If you mean GC-visible object graph tax, say GC-visible object graph tax.
If you mean JVM tax, then I want to see the JVM part.
So I took a deliberately boring question: What happens if Java, through the official Apache Arrow Java SDK, reads Arrow buffers, writes Arrow buffers, and runs a simple vectorized arithmetic kernel over them?
No Spark. No scheduler. No shuffle. No stage boundaries. No blocking distributed execution model. No network. No Spring Boot. No Stream<Integer>. No object-per-value data plane. Just modern Java, the official Apache Arrow Java SDK, java.lang.foreign.MemorySegment, the JDK Vector API, JMH, and the corresponding arithmetic kernels from arrow-rs as a production native Arrow reference point.
And no, this is not Java vs Rust. I am not comparing int[] with Vec<i32>, or Java collections with Rust collections. I am comparing kernel paths over Arrow-style columnar memory. One happens to be implemented in Java. One happens to be implemented in arrow-rs. The interesting question is not which mascot wins. The interesting question is whether the alleged JVM tax shows up when the memory layout and the kernel shape are comparable. Not because this explains all of Big Data performance. It obviously does not. But because if the claim is that a warmed-up JVM is inherently bad at executing analytical kernels over modern columnar memory, this is a pretty good place to look for the tax.
Setup: boring modern Big Data
The setup is intentionally boring.
I did not invent a custom memory layout. I did not write a native helper. I did not use JNI. I did not use sun.misc.Unsafe. I did not try to bypass the JVM. I used the thing modern analytical systems already use as a boundary: Apache Arrow.
Read Introducing Apache Arrow: Columnar In-Memory Analytics if you want to understand better what I meant.
More specifically, on the Java side:
- official Apache Arrow Java SDK:
16.1.0 - JDK:
25.0.3-temurin java.lang.foreign.MemorySegment- JDK Vector API:
jdk.incubator.vector - JMH:
0.7.3
On the native reference side:
arrow-rs:56- benchmark harness:
criterion = 0.5
Hardware:
- machine: my lovely ThinkPad with cozy Neon Genesis Evangelion stickers
- CPU: 13th Gen Intel(R) Core(TM) i5-1335U
- RAM: 38 GB
- OS: Fedora Linux, kernel 7.0.4
- notes: I watched Made in Abyss in the background, because this is a blog post, not SIGMOD
Java side
The Java implementation has three layers:
- raw compute:
computeAll(MemorySegment left, MemorySegment right, MemorySegment out, int n) - typed Arrow wrapper:
eval(IntVector left, IntVector right, IntVector out) - public dispatch API:
eval(FieldVector left, FieldVector right, FieldVector out)
The first layer is just a raw number-crunching loop. It does not know what Arrow is. It sees value buffers and a length. The second layer is where Arrow starts to matter: safe/valid input checks, null handling, output validity, and the boring Arrow-vector-to-memory-segment-to-Arrow-vector flow. The third layer is the public API: take generic FieldVector's, look at their Arrow types, pick the right implementation, and get out of the way.
There is one design difference that someone will probably call cheating, but I call it idiomatic Java. The arrow-rs arithmetic API returns a new Arrow array. Maybe this is the right API shape for Rust: ownership is clear, the result is explicit, allocations are cheap enough, and the library design stays clean. Fine. But I am not writing Rust in Java syntax. In JVM Big Data hot paths — Spark, Flink, Trino, and friends — the boring old trick is to allocate scratch/output state around the executor/operator/task boundary and reuse it. ThreadLocal holders, reusable vectors, builders, pages, blocks, buffers — this is normal JVM engine code. So my Java implementation is shaped like Java engine code, not like a literal port of arrow-rs. It accepts output vectors, resolves buffers, handles Arrow validity, and then gets out of the way. If that means the allocation profile is not identical, good. That is the point. This is not a language cage match. It is not Rust vs Java or JIT vs AOT. It is tool vs tool, used idiomatically. And the claim I care about is not "can I perfectly clone the arrow-rs API on the JVM?" The claim is: can modern Java implement Arrow-style analytical kernels without paying some mysterious JVM tax? My local answer is: yes, apparently it can.
Native side
On the native side I used the corresponding arithmetic kernels from arrow-rs as a production Arrow reference point.
- I did not write a custom native SIMD loop.
- I did not tune a special benchmark-only kernel.
- I did not try to make the native side look bad.
The point is not to compare my tiny Java loop with the best possible hand-written native loop. The point is to compare Arrow-shaped kernel paths.
A note on compiler flags. Yes, the native side was probably running with a conservative baseline like SSE2 while HotSpot used everything the CPU offered. This is not a bug in the benchmark — this is the benchmark. The claim "JVM needs tuning" goes both ways: I ran a default JVM against a default native build. If you want to argue that I should have rebuilt arrow-rs with RUSTFLAGS="-C target-cpu=native", fine — but then concede that "JVM specializes to the actual CPU automatically" is a feature, not noise. I am a Data Engineer, not a target-feature-matrix expert.
Note about Arrow
One important detail: Arrow did not make this easier. If I wanted the simplest possible Java microbenchmark, I would skip Arrow entirely, allocate three raw MemorySegments, and run Vector API over them. That would be less code and probably faster. I used Arrow because Arrow is the real boundary. It is what modern analytical systems use to avoid turning data into language-specific object graphs. It is not a trick to escape Java. It is how Big Data systems avoid object-layout tax in the first place. So the absence of object-per-value overhead or GC-visible data in the hot path is not a special optimization I wrote. It is what naturally happens when the data plane is Arrow buffers.
Results
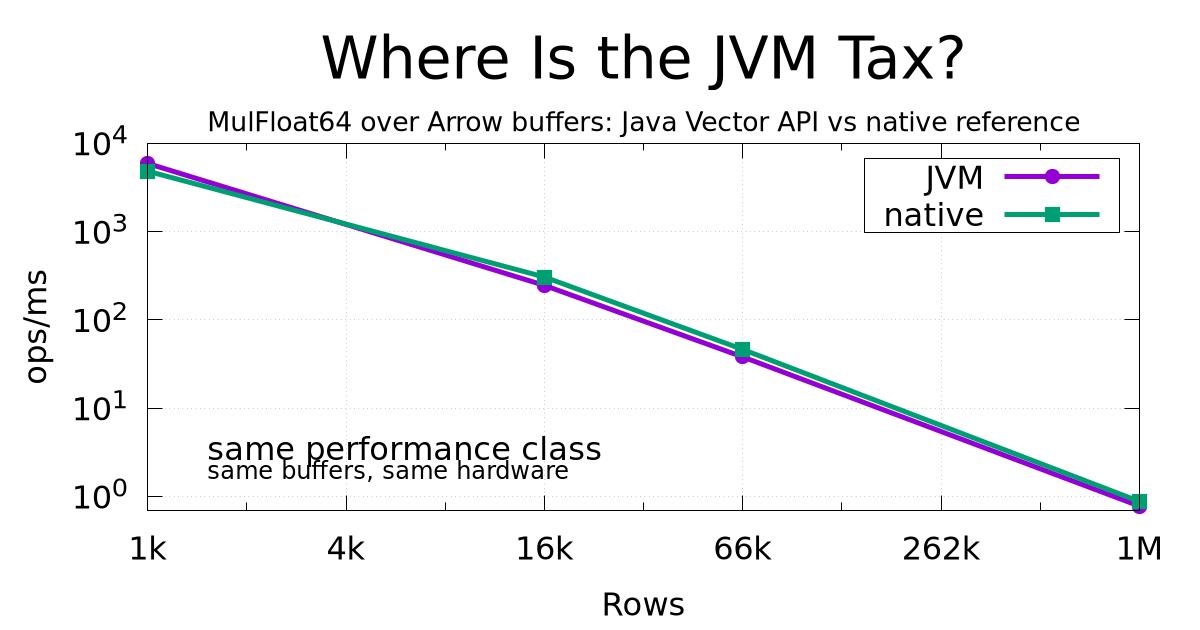
I would mostly look at MulFloat64 as the boring and useful result:
| rows | MulFloat64 JVM | MulFloat64 native | ratio |
|---|---|---|---|
| 1024 | 5906 | 4830 | JVM 1.22× |
| 16 384 | 246 | 306 | native 1.25× |
| 65 536 | 38.1 | 46.3 | native 1.22× |
| 1 048 576 | 0.78 | 0.88 | native 1.13× |
Given the noise, laptop setup, different harnesses, small semantic/API differences, and the fact that I was not trying to overfit either side, I read these numbers as “roughly the same performance class”. Sometimes native is a bit faster, sometimes Java is a bit faster, and at larger sizes everything starts looking like the usual hardware story: cache, L2/L3 behavior, memory bandwidth, CPU frequency, and the exact shape of the loop. In other words: not a giant JVM tax, just the machine being the machine.
Please don't read too much into the AddInt32 numbers. They're mostly just for fun, so read the note below before sharing them!
| rows | AddInt32 JVM | AddInt32 native | ratio* |
|---|---|---|---|
| 1024 | 8065 | 994 | JVM 8.11× |
| 16 384 | 441 | 58.4 | JVM 7.55× |
| 65 536 | 106 | 14.6 | JVM 7.26× |
| 1 048 576 | 2.28 | 0.856 | JVM 2.66× |
*This is mostly a semantics mismatch, not a miracle. In the JVM world, integer addition normally wraps: Integer.MAX_VALUE + 1 == Integer.MIN_VALUE. My Java kernel follows that behavior. The arrow-rs add path, as far as I understand it, uses checked arithmetic semantics, and this seems to prevent the hot loop from vectorizing in the same way. That probably explains the huge gap. Again, the goal of this experiment is not to reimplement arrow-rs on the JVM with exactly the same API and semantics. The goal is to write idiomatic Java for this kind of data-engine hot path and ask whether the alleged JVM tax appears there.
A small checklist for the alleged JVM tax
Some modern "Spark killer" engines like to explain the JVM tax with a checklist like this:
no garbage collection pauses, no JVM memory tuning, low memory footprint
I genuinely love a lot of the engineering behind these systems. I even contributed to Apache Datafusion Comet (in Rust), so this is not some anti-native-engine rant. I just dislike the slogan.
Let’s apply the checklist to this Java code.
GC pauses?
The hot data path is Arrow buffers, not Java objects. No Integer per value, no object graph, no row objects, no Java serialization in the kernel. Output buffers are caller-provided and can be reused in the usual JVM data-engine style. GC exists, but it does not own the data plane.
JVM memory tuning?
I did not tune the JVM. I used a default Temurin JDK 25 and ran JMH. If anything, the side that probably needs more tuning is the native one: compiler flags, target CPU, feature dispatch, build profiles, and portable binary choices. That is not JVM tax. That is deployment and compiler tax.
Low memory footprint?
The memory footprint is Arrow. Literally. Same primitive buffers, same columnar layout, same hardware-facing representation. There is some constant overhead from a usable public API: dispatch, wrappers, checks, and library semantics. But if that is "JVM tax", then every function call in every engine is a tax.
So if this is the checklist, the conclusion is simple: the advertised JVM tax is not intrinsic to the JVM. It is mostly a consequence of putting analytical data in the wrong memory architecture.
FAQ / expected objections
“But you used Arrow. Isn’t that cheating?”
If I wanted the simplest Java microbenchmark, I would skip Arrow completely: allocate three raw MemorySegments, run Vector API over them, and avoid Arrow vectors, validity buffers, allocators, schemas, and lifecycle rules.
I used Arrow because Arrow is the modern analytical memory boundary. DataFusion, PyArrow, Polars, Flight, IPC, and a large part of the modern data ecosystem are built around the same idea: stop turning analytical data into language-specific object graphs.
If JVM tax only appears when Java is forced to use the wrong memory layout, then it was not JVM tax. It was layout tax.
“But this is not real Java.”
If the "real" Java is Stream<Integer>.reduce(...), then compare it with "real" native:
std::vector<std::shared_ptr<int32_t>>with pointer chasing, refcount traffic, allocator pressure, and terrible cache locality.
My code is 100% Java. No JNI, no .so, no Unsafe. Show me what exactly is "not real Java" in this snippet:
public final class AddInt32Raw {
public static final VectorSpecies<Integer> SPECIES = IntVector.SPECIES_PREFERRED;
public static final ValueLayout.OfInt INT32_LE = ValueLayout.JAVA_INT_UNALIGNED.withOrder(ByteOrder.LITTLE_ENDIAN);
public static final ByteOrder BYTE_ORDER = ByteOrder.LITTLE_ENDIAN;
private AddInt32Raw() {}
public static void computeAll(MemorySegment left, MemorySegment right, MemorySegment out, int n) {
int i = 0;
int upper = SPECIES.loopBound(n);
for (; i < upper; i += SPECIES.length()) {
long off = (long) i * Integer.BYTES;
var x = IntVector.fromMemorySegment(SPECIES, left, off, BYTE_ORDER);
var y = IntVector.fromMemorySegment(SPECIES, right, off, BYTE_ORDER);
x.add(y).intoMemorySegment(out, off, BYTE_ORDER);
}
for (; i < n; i++) {
long off = (long) i * Integer.BYTES;
int x = left.get(INT32_LE, off);
int y = right.get(INT32_LE, off);
out.set(INT32_LE, off, x + y);
}
}
}“But Vector API is incubating.”
Yes. In Java. Which means something very different from "random unstable toy".
Vector API is an explicit opt-in, non-final API. Java is extremely conservative about freezing APIs into the platform forever, so “incubating” often means “not ready to support this exact API shape until retirement”, not “this barely works”.
“But JIT warmup.”
This is Big Data, not firmware. A five-hour batch job over terabytes of data is not a cold-start benchmark. A 24/7 streaming job is not a Lambda function. Long-running JVM processes are supposed to warm up. If your workload is a CLI tool, an embedded database, a short-lived process, or a serverless function, then yes, cold start matters. Maybe you should use DuckDB, native code, WASM, or something else.
“But this is not Spark.”
Correct. Then call it Spark tax, not JVM tax.
Spark has scheduler overhead, shuffle overhead, spill, fault tolerance, query planning, stage boundaries, skew, storage, network, row/column transitions, and legacy execution-model costs.
Some of that runs inside a JVM process. That does not magically make it JVM tax.
- If you mean Spark tax, say Spark tax.
- If you mean shuffle tax, say shuffle tax.
- If you mean scheduler tax, say scheduler tax.
- If you mean JVM tax, show me where it is in this pure Java kernel.
“But real systems are end-to-end.”
"End-to-end" is not a root cause. It is a box. Open the box. Where exactly does the native engine win?
Is it the arithmetic kernel? The memory layout? The nullability semantics? The hash table? The string representation? The Parquet reader? The shuffle protocol? The scheduler? The plugin model? The deployment story?
If the answer is "columnar memory, vectorized execution, and avoiding object graphs", then that is not native magic. Java can use columnar Arrow memory too.
“But this is not Java vs Rust.”
Correct. It is not Java vs Rust. I am not comparing int[] with Vec<i32>. I am not comparing Java collections with Rust collections. I am not comparing mascots.
“But Arrow Java is not the same thing as native Arrow.”
Sure. Different implementation, different API, different trade-offs. But Java is not a tourist in the Arrow ecosystem. Arrow Java is an official part of Apache Arrow, an Apache Software Foundation top-level project. It is not a random third-party wrapper, not JNI glue, and not a toy side project. If your definition of "real Big Data" includes Arrow but excludes Arrow Java, that is not a technical argument.
One more thing: the JVM is not only a tax
If raw kernel performance is roughly the same class, then the next question is not "how do we escape the JVM?" The next question is: What else does the runtime give us?
And here the JVM is annoyingly good.
Dynamic code loading
In JVM-land, shipping new code is often "put a JAR on the classpath / load a class". In native-land, this quickly becomes ABI hell, .so compatibility, unsafe plugins, WASM tax, sidecar processes, IPC, and fun with resource management.
Moving from Xeon to Graviton
In JVM-land, this can be as boring as changing an AWS instance type and running the same JAR. In native-land, this can become "let's spend two weeks checking compiler flags, target CPUs, feature dispatch, build profiles, CI artifacts, and whether our wheels/binaries actually use the right instructions".
CPU dispatch on the actual machine
A portable native binary is only "close to metal" after you ask: which metal? The JVM compiles hot code on the machine where it actually runs. That is not a tax. That is a feature.
Memory safety by default
This code uses MemorySegment and Vector API, not Unsafe pointer soup. Yes, the JVM can be crashed with JNI, Unsafe, native libraries, or enough creativity. But ordinary modern Java is not built around “one bad pointer and goodbye process”.
One runtime, one operational surface
Metrics, profiling, memory pressure, class loading, task lifecycle, cancellation, logging, debugging, and observability can live in one process and one runtime. Replacing JVM tax with IPC tax, WASM tax, ABI tax, allocator tax, or “two processes on localhost pretending to be one engine” tax is not automatically a win.
Boring orchestration
Query planning, connectors, catalogs, security integrations, retries, scheduling, configs, plugins, and UDF loading are not SIMD loops. They are boring platform work. The JVM is very good at boring.
The JVM is not just "tax" which you barely can measure for modern idiomatic Java code. JVM is also a very serious runtime services bundle. If your hot loop is already in the same performance class, you need a better argument than vibes about bytecode.
Afterword: where this experiment says nothing
This experiment is intentionally narrow.
It says almost nothing about the hard parts of analytical engines:
Decimals. Decimal arithmetic is its own world: precision, scale, overflow rules, larger-than-machine-word values, and much less obvious SIMD story. Strings / UTF-8. Variable-width data is where life gets interesting: offsets, validity, UTF-8 validation, comparison, hashing, slicing, dictionary encoding, and branch-heavy code. Nested types. Lists, structs, maps, unions — this benchmark does not touch any of that. Nested Arrow layouts are powerful, but they are not "just add two buffers". Hash aggregation / joins. Hash tables are not simple arithmetic kernels. Layout, probing strategy, resizing, cache locality, null semantics, string keys, spilling, and skew can dominate everything. Parquet I/O. Reading Parquet is a very different benchmark: decoding, compression, page layout, predicate pushdown, dictionary decoding, nested schemas, I/O, and implementation maturity. End-to-end query execution Planning, scheduling, operator fusion, memory accounting, spilling, backpressure, metrics, cancellation, and resource isolation are not measured here.
This post proves only:
For simple arithmetic kernels over Arrow-style columnar memory, I could not find a magical JVM tax.
Everything else still has to be measured.
Acknowledgements
This post would not exist without Stratum, which gave me the initial idea that modern JVM-based analytical execution is much more interesting than the usual "JVM tax" folklore suggests. It also would not exist without OpenCode, Codex 5.3, and open-spdd. They made it possible to vibe-code the experiment, iterate on the kernels, write the benchmark scaffolding, and get something interesting running in just a couple of evenings.
As usual, all bugs, wrong conclusions, and overly opinionated takes are mine.