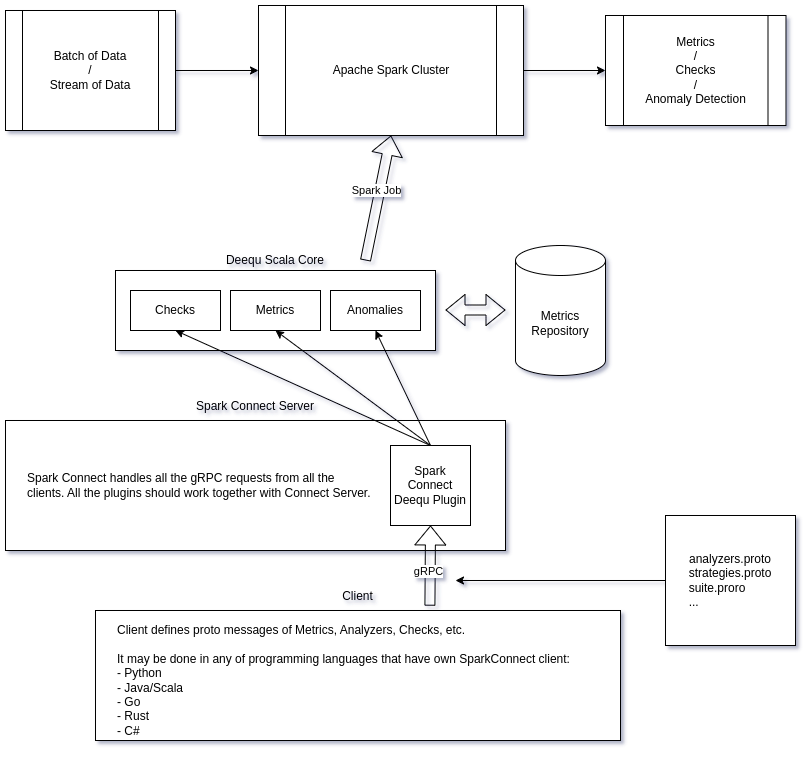
Summary
This blog post is a detailed story about how I ported a popular data quality framework, AWS Deequ, to Spark-Connect. Deequ is a very cool, reliable and scalable framework that allows to compute a lot of metrics, checks and anomaly detection suites on the data using Apache Spark cluster. But the Deequ core is a Scala library that uses a lot of low-level Apache Spark APIs for better performance, so it cannot be run directly on any of Spark-Connect environment. To solve this problem, I defined protobuf messages for all main structures of Deequ, like Check, Analyzer, AnomalyDetectionStrategy, etc., wrote a helper object that can re-create Deequ structures from the corresponding protobuf, and finally made a Spark-Connect native plugin that can process Deequ specific messages, construct DQ suits from them, compute the report, and return the result to the Spark-Connect client. I tested my solution with PySpark Connect 3.5.1, but it should work with any of the existing Spark-Connect clients (Spark-Connect Java/Scala, Spark-Connect Go, Spark-Connect Rust, Spark-Connect C#, etc).
How the post is organized?
The first part is a brief introduction to the domain: if you know what SparkConnect is and why libraries that rely on a low-level Apache Spark API are not compatible with it, you can skip it.
The next part is a brief overview of the AWS Deequ Data Quality framework. How it works, why I think it is cool, and why I love it. I will also briefly mention the existing python-deequ wrapper and why I decided to make an alternative one.
The main part is about defining the main proto-messages to be able to serialize the whole Deequ VerificationSuite. I will also show how to implement the corresponding Spark-Connect plugin.
At the end there will be my personal thoughts about the current state of the Spark-Connect ecosystem and how I'm starting to love it!
Pre-requisites
- minimal understanding of Apache Spark;
- an ability to read simple Scala code;
- an ability to read simple Python code;
- minimal understanding of protobuf messages syntax.
You can also read my previous post on extending Spark-Connect. In that post I made a very detailed guide about the basic concepts of Spark-Connect, about writing plugins for it and about working with Spark protobuf messages. The current post is less detailed and focuses on the practical exercise of poring the existing Scala library to Connect.
Introduction
Spark-Connect
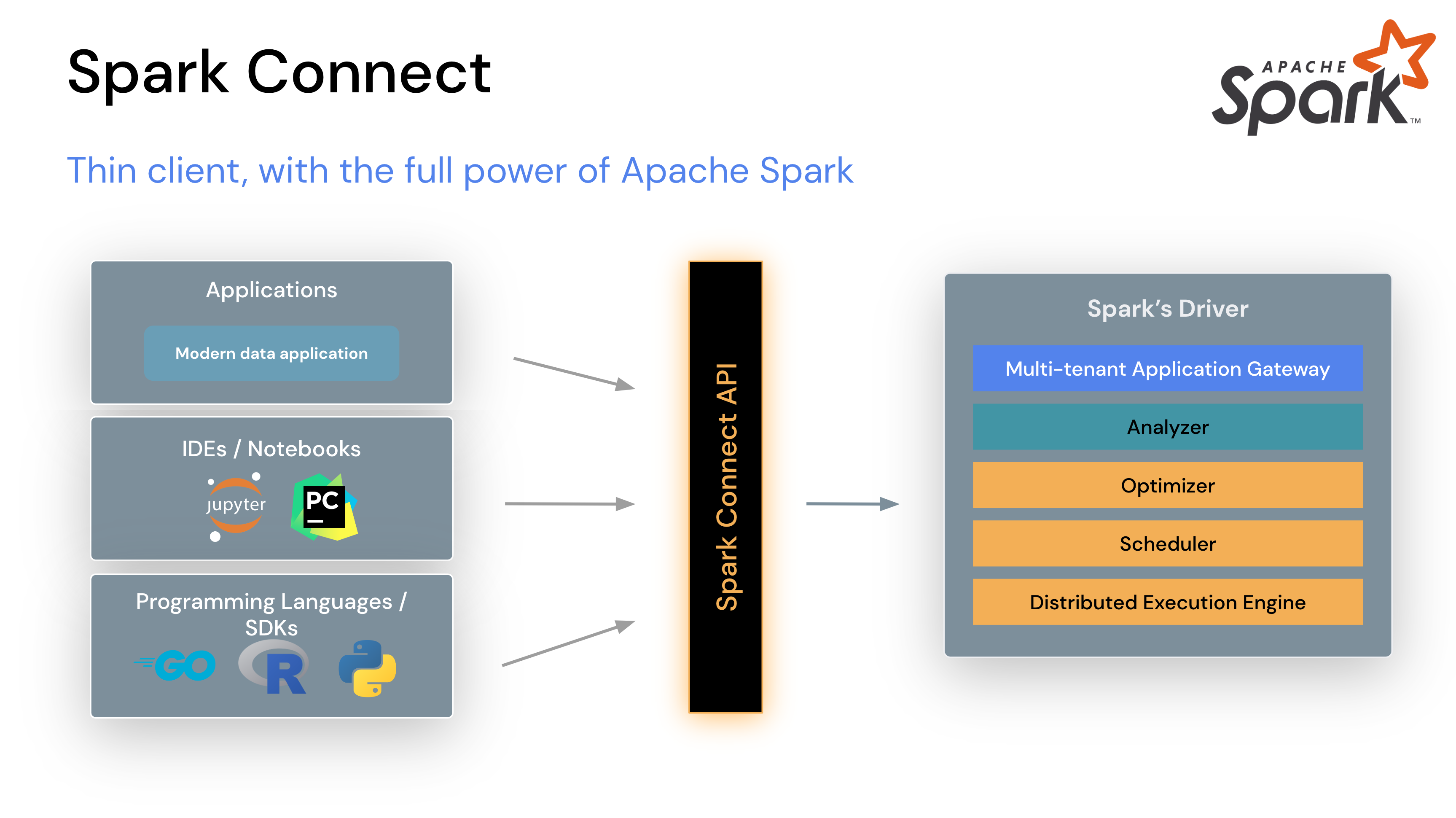
Spark-Connect is a modern client-server architecture paradigm for the Apache Spark engine. It splits the monolithic client-driver Spark application by separating the driver. Let's assume for simplicity that we are running the Spark application in a so-called client mode. Then, for Spark Classic, we need all the Apache Spark components and configuration. For example, we need to have all Spark-related JAR files in the ClassPath of the program. And we need to set up Java. And resolve all Spark dependencies… And finally, we need all the ips of the nodes. And maybe even Hadoop binaries with the appropriate Hadoop XML configurations. Of course, this excludes the possibility of connecting to Spark Cluster from the IDE, for example. And the whole process and on-boarding can become very difficult.
The previous attempt to resolve this problem was in a separate Apache project named Apache Livy (incubating). But at the moment Livy looks completely abandoned and dead.
So the best solution right now is Apache Spark Connect. It is not only maintained by the core team of Spark developers, but also allows to create clients in many languages, not only those officially supported by Apache Spark. For example, you can check out the Spark-Connect Go project, which allows you to define Spark jobs natively from Golang, without needing to set up or call Java.
How Spark-Connect works?
Spark-Connect uses gRPC to send commands and Arrow Flight to send data. The main structure of Spark-Connect protobuf messages is a Plan, which can become a Command or a Relation. The command is not so interesting for us because it is for when we do not need feedback from the server. On the contrary, a Relation is the most interesting object in Spark-Connect. Remember, all transformations (read, join, select, group by, etc.) in Apache Spark are lazy until you call an action (write, collect, etc.). Thus, the Relation message in the Spark connect protobuf part is a sequence of transformations, also called an Unresolved Logical Plan.
NOTE: For anyone who is not very familiar with Unresolved Logical Plan, Analyzed Logical Plan, Physical Plan, etc. in Apache Spark I can recommend to read a paper Spark SQL: Relational Data Processing in Spark or a book from Andy Grove that is named How query engines work.
Inside the definition of the Relation message you can find the following:
message Relation {
RelationCommon common = 1;
oneof rel_type {
Read read = 2;
Project project = 3;
Filter filter = 4;
Join join = 5;
SetOperation set_op = 6;
Sort sort = 7;
Limit limit = 8;
Aggregate aggregate = 9;
SQL sql = 10;
LocalRelation local_relation = 11;
Sample sample = 12;
Offset offset = 13;
...
// NA functions
...
// stat functions
...
// Catalog API (experimental / unstable)
Catalog catalog = 200;
// This field is used to mark extensions to the protocol. When plugins generate arbitrary
// relations they can add them here. During the planning the correct resolution is done.
google.protobuf.Any extension = 998;
Unknown unknown = 999;
}
}So, when you write a command (like df = spark.read.parquet("sales.parquet")) in Spark-Connect environment, your client (PySpark Connect, Spark-Connect Go, etc.) just pack the step of the plan into Relation message with a rel_type equal to Read. If you call something like df2 = df.filter("city = 'Belgrade'") then a new relation with type Filter will be sent to the Server.
For a top-level overview, you can check out also an Overview in Spark Documentation. For a deeper dive into the topic I recommend this nice blog post by Bartosz Konieczny or the video of Martin Grund's presentation:
Spoiler about extending the Spark-Connect Protocol
The message with a number 998 that is named extension and has a type google.protobuf.Any is the placeholder for a user-defined Relation. But we will discuss it in details little later.
A problem of Spark-Connect for the Apache Spark ecosystem
Spark-Connect is definitely number one if you need nothing more than the built-in Apache Spark APIs. The problems start when you need to work with a library that uses some of the low-level Apache Spark APIs. Even if the library only uses the RDD API, which is still public in Spark Classic, that library won't work with Spark-Connect out of the box.
A quote from the Apache Spark Docs:
PySpark: In Spark 3.4, Spark Connect supports most PySpark APIs, including DataFrame, Functions, and Column. However, some APIs such as SparkContext and RDD are not supported. You can check which APIs are currently supported in the API reference documentation. Supported APIs are labeled “Supports Spark Connect” so you can check whether the APIs you are using are available before migrating existing code to Spark Connect.
Scala: In Spark 3.5, Spark Connect supports most Scala APIs, including Dataset, functions, Column, Catalog and KeyValueGroupedDataset.
User-Defined Functions (UDFs) are supported, by default for the shell and in standalone applications with additional set-up requirements.
Majority of the Streaming API is supported, including DataStreamReader, DataStreamWriter, StreamingQuery and StreamingQueryListener.
APIs such as SparkContext and RDD are deprecated in all Spark Connect versions.
So if the library depends on the RDD API, you cannot just run it as is. Another problem is the packages from the Apache Spark ecosystem that rely on py4j to create a PySpark binding to the Java/Scala library. I wrote a blog post about this where I found a lot of popular open source libraries that don't work in a Spark-Connect environment. It's a long story, but after that post, I had a meeting with Martin Grund and he convinced me that using py4j was a bad idea from the start to begin with, and that library developers should start migrating to a native Spark-Connect plugins. The arguments for the native connect plugins are strong: you have to create protobuf messages once and it will work in any connect environment. And you are not relying on PySpark's non-public APIs like SparkSession._jvm in this case.
And that is exactly the goal of my post: to make a good and well documented example, how an existing low-level Apache Spark library can be migrated to Spark-Connect ecosystem!
AWS Deequ
AWS Deequ is a very popular (3.2k stars on GitHub) Data Quality framework.
Schelter, S., Lange, D., Schmidt, P., Celikel, M., & Biessmann, F. (2018). Automating large-scale data quality verification.
- Source code: https://github.com/awslabs/deequ
- Paper: https://www.amazon.science/publications/automating-large-scale-data-quality-verification
- Paper: https://www.amazon.science/publications/unit-testing-data-with-deequ
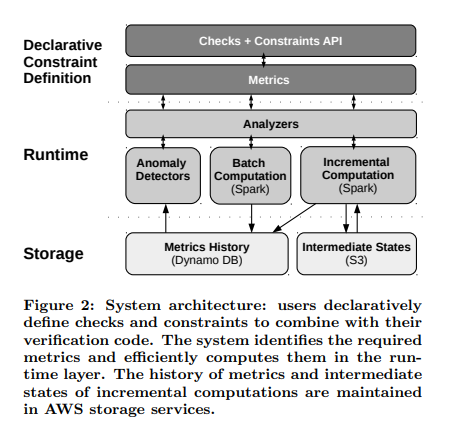
Why I'm thinking Deequ is so cool?
While there are many "unified" and "multi-engine" data quality tools available today, I still find Deequ to be the best choice for Apache Spark workloads. Why is that? Well, there are a few reasons.
Deequ is built natively for Apache Spark and with Apache Spark's native language Scala. Instead of using a top level public APIs like Dataset / Dataframe API, Deequ does it better. One of the main concept of Deequ is Analyzer[S :< State[S], Metric[T]]. It is not just a SQL query like count(when(col("x").isNotNull()), because under the hood Deequ combines all states into a custom Accumulator and runs a custom Map-Reduce on the data. Because of that approach Deequ can compute most of the required metrics in a single loop over the data. In most cases, this allows you to compute an unlimited number of metrics, including not only scalars (count of non-nulls, for example), but with any arbitrary State that can contain a lot of results.
State in Deequ:
/**
* A state (sufficient statistic) computed from data, from which we can compute a metric.
* Must be combinable with other states of the same type
* (= algebraic properties of a commutative semi-group)
*/
trait State[S <: State[S]] {
// Unfortunately this is required due to type checking issues
private[analyzers] def sumUntyped(other: State[_]): S = {
sum(other.asInstanceOf[S])
}
/** Combine this with another state */
def sum(other: S): S
/** Same as sum, syntatic sugar */
def +(other: S): S = {
sum(other)
}
}NOTE: Just look at how well the code is documented. How often do you see such well-written comments in an open source library? These are comments on the code, with insertions from the textbook on category theory. This is what I call "written by engineers for engineers"!
Or, for example, take a look on a ScanSharableAnalyzer in Deequ. It is a trait that allows to create an Analyzer that partially share the State with another Analyzer!
/** An analyzer that runs a set of aggregation functions over the data,
* can share scans over the data */
trait ScanShareableAnalyzer[S <: State[_], +M <: Metric[_]] extends Analyzer[S, M]Another strong point of Deequ for me is that it is an engine to calculate metrics and profile the data. The developers of Deequ are not trying to create just-another-boring-yaml-low-code-tool. Instead, they provide a very well-designed and easily extensible core that allows you to compute a lot of things on really huge datasets. And if you need a jinja2 templated low-code tool, it is easy to build it on top of deequ. And unlike existing low-code solutions (mostly paid), the advantage of building your own on top of a strong core is obvious: you can bring a domain knowledge of your specific cases into the organization of jinja2 / yaml / json configurations. I have done this twice in my career. Believe me, building a low-code solution on top of such a well-designed library as Deequ is a breeze!
Anomaly Detection
I'm an engineer who works in ML/MLE team as a person who provides a data engineering support to brilliant minds: Data Scientists, people who know math and have Ph.D.'s. You can say that I'm not a data engineer but a MLOps engineer, but I absolutely agree with a statement that "MLOps is 98% data engineering". But working with ML/DS topics is a bit different from building a DWH. For example, I can see that most existing DQ tools do not provide something like anomaly detection (or relative constraints). For example, there is nothing like this in a popular DQ tool Great Expectations. I do not know, maybe it is not necessary for DWH development. But for my tasks it is, and let me explain why.
Let me first define a term "anomaly detection" as it is used in my post (and in Deequ concepts). Anomaly Detection is when we have not only static constraints, but also a relative constraint of how data is changing over time. For example, if I have data that contains customer transactions, it is hard to define reasonable static constraints for metrics like avg or median. Simply because no one really knows. But what we can definitely define is allowed data drift. For example, if I know that inflation is below 10%, then I can say with confidence that this week's average spend should not vary from last week's average spend. I can define the boundaries, like +-10%, and say that if the new batch of data does not fit within those boundaries, it is a very dangerous sign!
AnomalyDetectionStrategy trait in Deequ:
/** Interface for all strategies that spot anomalies in a series of data points. */
trait AnomalyDetectionStrategy {
/**
* Search for anomalies in a series of data points.
*
* @param dataSeries The data contained in a Vector of Doubles
* @param searchInterval The indices between which anomalies should be detected. [a, b).
* @return The indices of all anomalies in the interval and their corresponding wrapper object.
*/
def detect(
dataSeries: Vector[Double],
searchInterval: (Int, Int) = (0, Int.MaxValue)): Seq[(Int, Anomaly)]
}Why is it important for ML/DS tasks? Simply because ML models are very sensitive to data quality, and at the same time ML features (the result of feature engineering) have such complex logic behind them that defining static constraints is almost impossible. This is also true for the output of ML models. For example, if you run batch ML inference every week to update user recommendations, you can expect that the distributions of product propensities should not drift dramatically between batches.
If you are interesting in that topic, you can check a presentation from my colleague Pavle Tabandzelic about how we are using PyDeequ for checking the stability of our batch ML inference process:
Of course, you can just write a window function in SQL and compare all the batches. But why do we need to scan all the data each time if we have already calculated all the metrics on previous batches? We just need to have a persistent state that is shared between runs of data quality suites. In Deequ, this is implemented through the concept of MetricRepository, a persistent store that holds the results of previous calculations:
/**
* Common trait for RepositoryIndexes where deequ runs can be stored.
* Repository provides methods to store AnalysisResults(metrics) and VerificationResults(if any)
*/
trait MetricsRepository {
/**
* Saves Analysis results (metrics)
*
* @param resultKey A ResultKey that uniquely identifies a AnalysisResult
* @param analyzerContext The resulting AnalyzerContext of an Analysis
*/
def save(resultKey: ResultKey, analyzerContext: AnalyzerContext): Unit
/**
* Get a AnalyzerContext saved using exactly the same resultKey if present
*/
def loadByKey(resultKey: ResultKey): Option[AnalyzerContext]
/** Get a builder class to construct a loading query to get AnalysisResults */
def load(): MetricsRepositoryMultipleResultsLoader
}Out of the box, Deequ provides few implementations for MetricRepository: in the form of an in-memory one, in the form of JSONs in the arbitrary (supported by org.apache.hadoop.fs) file system, and also in the form of the Spark table (which can be anything from CSV to Delta/Iceberg). You can also create your own implementation of the MetricRepository trait. For example, this repository provides an InfluxDB implementation for Deequ. I'm sure that there are more of them.
Finally, Deequ is a non-commercial library (there is nothing like an "open source" repository with an "enterprise branch"). It is a tool built and maintained by Amazon engineers for their own needs, as Deequ is tightly integrated with Glue Catalog. So with Deequ I can be sure that there won't be anything like "license change" or similar. It is a library made by engineers for engineers, not something made by marketing department for best sales. So, as you might understand, I love Deequ, so forgive me this little bias :D
In the end, the goal of the post is to show an example of porting an existing Scala library to Spark-Connect and I just tried to explain why Deequ was chosen by me.
A brief introduction into Deequ APIs
The top level object in Deequ is a VerificationSuite. But in 99% of cases you will not need to work with it directly because you will be using a builder.
VerificationSuite can contain the following:
- A data that is
org.apache.spark.sql.DataFrame; - An optional sequence of
Analyzerobjects that should be run anyway to compute the required metrics. This is a case where you do not want to define constraints, but want to describe your data; - An optional sequence of
Checkobjects that are actually a pair ofAnalyzerobjects and a lambda function that takes a metric from theAnalyzerand returnsBoolean; - An optional sequence of
AnomalyDetectioncases that are actually a combination ofAnalyzerandAnomalyDetectionStrategy; - An optional
MetricReportandResultKeythat uniquely identify the data.
Let's see on a minimal basic example from the Deequ repository:
val verificationResult = VerificationSuite()
.onData(data)
.addCheck(
Check(CheckLevel.Error, "integrity checks")
// we expect 5 records
.hasSize(_ == 5)
// 'id' should never be NULL
.isComplete("id")
// 'id' should not contain duplicates
.isUnique("id")
// 'productName' should never be NULL
.isComplete("productName")
// 'priority' should only contain the values "high" and "low"
.isContainedIn("priority", Array("high", "low"))
// 'numViews' should not contain negative values
.isNonNegative("numViews"))
.addCheck(
Check(CheckLevel.Warning, "distribution checks")
// at least half of the 'description's should contain a url
.containsURL("description", _ >= 0.5)
// half of the items should have less than 10 'numViews'
.hasApproxQuantile("numViews", 0.5, _ <= 10))
.run()There we define a suite on the data (in this case it is just a toy dataset of 5 rows, see the definition in the Deequ repository), requiring that the data should have 5 rows, the "id" column should be complete or have no null values, the "id" column should contain only unique values, etc.
A brief overview of PyDeequ: why I need another wrapper?
I understand that you are probably already tired of my impression of Deequ. But before we go to the main topic of Spark-Connect, let me add one more remark about why I decided to make another wrapper on top of Deequ when there is a python-deequ project maintained by the same Amazon engineers.
The py4j problem. An existing Python Deequ wrapper relies on calls to private APIs of PySpark. It starts by calling SparkSession._jvm to get access to JVM and call Scala classes directly from Python via Java bridge. And it is a problem: First of all, this approach does not work in PySpark Connect and there is no way to make it work except porting the whole py4j library to Spark-Connect. Another problem is that py4j is designed to work with Java code, not Scala. And sometimes it can be very hard to maintain bindings to Scala! It creates a big trade-off between maintainability of Python bindings and using the most advanced feature of Scala programming language.
NOTE: If you want to have fun, try to imagine how to create an
Option[Long]from a Python value100usingpy4j. Spoiler:scala.Option(java.lang.Long.valueOf(100))won't work. Because in the first step Python will call the expression in brackets. It will create aLong(100)in JVM, but after getting the result,py4jwill do automatic unboxing of Java types into Python types and result in Python will be just100. And the next step is callscala.Option(100):py4jwill send100to the JVM and do automatic boxing of the value, but because100is less thanjava.lang.Integer.MAX_VALUE, it will create ajava.lang.Integer(100)in the JVM. So the result will beOption[Integer]instead of the desiredOption[Long]. And there are many such corner cases. PyDeequ devs even created their own set of utilities to work with Scala frompy4j, but of course it cannot cover all cases.
The lack-of-maintenance problem. If you go the issues page of the python-deequ project you may see that a typical gap between the support of the new version of the Apache Spark in the core Deequ and the support of that version in python-deequ may become months (or even years). I'm not that person who may come to the public open-source library and start arguing in the manner like I'm paying to devs and there is a service-level-agreement between us. By the end it is Open Source, no one have a duty there. I'm just happy that engineers from Amazon decided to put their tool to Open Source and I have zero rights to require more! But what I can do is to try to make my own wrapper on top of a beautiful Deequ core using a modern Spark-Connect and protobuf approach!
Making a Spark-Connect plugin for Deequ
As mentioned above, to create a Spark Connect plugin, you need to do the following
- Define a custom extension in protobuf;
- Write a plugin to handle these types of messages.
Defining protobuf messages
Let's start from defining protobuf.
Analyzers
I made a decision to make Analyzer object in the form of oneof that may contain all possible implementations of analyzers in Deequ.
message Analyzer {
oneof analyzer {
ApproxCountDistinct approx_count_distinct = 1;
ApproxQuantile approx_quantile = 2;
ApproxQuantiles approx_quantiles = 3;
ColumnCount column_count = 4;
Completeness completeness = 5;
Compliance compliance = 6;
Correlation correlation = 7;
CountDistinct count_distinct = 8;
CustomSql custom_sql = 9;
DataType data_type = 10;
Distinctness distinctness = 11;
Entropy entropy = 12;
ExactQuantile exact_quantile = 13;
Histogram histogram = 14;
KLLSketch kll_sketch = 15;
MaxLength max_length = 16;
Maximum maximum = 17;
Mean mean = 18;
MinLength min_length = 19;
Minimum minimum = 20;
MutualInformation mutual_information = 21;
PatternMatch pattern_match = 22;
RatioOfSums ratio_of_sums = 23;
Size size = 24;
StandardDeviation standard_deviation = 25;
Sum sum = 26;
UniqueValueRatio unique_value_ratio = 27;
Uniqueness uniqueness = 28;
}
}NOTE: To be honest I have a very limited experience with
protobuf, so I just made a decision to not invent a wheel and copy that "oneof-based" pattern of converting an API to protobuf messages from Apache Spark Connect code.
Let's take one of analyzers as example to see how protobuf message is related to the Deequ case class signature:
case class Compliance(instance: String,
predicate: String,
where: Option[String] = None,
columns: List[String] = List.empty[String],
analyzerOptions: Option[AnalyzerOptions] = None)And the message that I defined for that analyzer:
message Compliance {
string instance = 1;
string predicate = 2;
optional string where = 3;
repeated string columns = 4;
optional AnalyzerOptions options = 5;
}As you may see it is almost 1to1 signature of the Deequ's case-class. One may say that it is not an easy task but I was able to cover about 90% of all the analyzers in Deequ in just about 230 lines of protobuf code. Anyway, if one wants to go a py4j way it will require even more code because of the pain with Scala Option and defaults that are hard to work with even from Java.
For parsing protobuf messages into Deequ structures I used explicit pattern-matching in the following style:
private[ssinchenko] def parseAnalyzer(analyzer: proto.Analyzer) = {
analyzer.getAnalyzerCase match {
case proto.Analyzer.AnalyzerCase.APPROX_COUNT_DISTINCT =>
val protoAnalyzer = analyzer.getApproxCountDistinct
ApproxCountDistinct(
protoAnalyzer.getColumn,
if (protoAnalyzer.hasWhere) Some(protoAnalyzer.getWhere) else Option.empty
)
....
case proto.Analyzer.AnalyzerCase.UNIQUENESS =>
val protoAnalyzer = analyzer.getUniqueness
Uniqueness(
protoAnalyzer.getColumnsList.asScala.toSeq,
if (protoAnalyzer.hasWhere) Some(protoAnalyzer.getWhere) else Option.empty,
parseAnalyzerOptions(Option(protoAnalyzer.getOptions))
)
case _ => throw new RuntimeException(s"Unsupported Analyzer Type ${analyzer.getAnalyzerCase.name}")
}
}Anomaly Detection Strategies
In an absolutely the same way I defined possible case-classes for AnomalyDetectionStrategy:
message AnomalyDetectionStrategy {
oneof strategy {
AbsoluteChangeStrategy absolute_change_strategy = 1;
BatchNormalStrategy batch_normal_strategy = 2;
OnlineNormalStrategy online_normal_strategy = 3;
RelativeRateOfChangeStrategy relative_rate_of_change_strategy = 4;
SimpleThresholdStrategy simple_thresholds_strategy = 5;
}
}Parsing of messages to Deequ is done in the same way like for analyzers:
private def parseAnomalyDetectionStrategy(strategy: proto.AnomalyDetectionStrategy) = {
strategy.getStrategyCase match {
case proto.AnomalyDetectionStrategy.StrategyCase.ABSOLUTE_CHANGE_STRATEGY =>
val protoStrategy = strategy.getAbsoluteChangeStrategy
AbsoluteChangeStrategy(
if (protoStrategy.hasMaxRateDecrease) Some(protoStrategy.getMaxRateDecrease) else Option.empty,
if (protoStrategy.hasMaxRateIncrease) Some(protoStrategy.getMaxRateIncrease) else Option.empty,
if (protoStrategy.hasOrder) protoStrategy.getOrder else 1
)
....
case proto.AnomalyDetectionStrategy.StrategyCase.SIMPLE_THRESHOLDS_STRATEGY =>
val protoStrategy = strategy.getSimpleThresholdsStrategy
SimpleThresholdStrategy(
if (protoStrategy.hasLowerBound) protoStrategy.getLowerBound else Double.MinValue,
protoStrategy.getUpperBound
)
case _ => throw new RuntimeException(s"Unsupported Strategy ${strategy.getStrategyCase.name}")
}
}Check and VerificationSuite
The first problem that I faced is that because Deequ is written in a true Scala way, instead of constraints it expects lambda expressions in form T => Bolean where T is the underlying value of the Metric. For example, hasSize(_ == 5) means that Deequ should compute the value of metric for the analyzer Size and pass it the function x => x == 5. And there is no obvious way to serialize Scala lambda expression from Python or Golang. So, I made a decision to use static constraints instead. My definition of Check in protobuf is the following:
message Check {
CheckLevel checkLevel = 1;
string description = 2;
repeated Constraint constraints = 3;
message Constraint {
Analyzer analyzer = 1;
oneof expectation {
int64 long_expectation = 2;
double double_expectation = 3;
}
ComparisonSign sign = 4;
optional string hint = 5;
optional string name = 6;
}
enum ComparisonSign {
GT = 0;
GET = 1;
EQ = 2;
LT = 3;
LET = 4;
}
}This trick would be impossible if Deequ Scala library wasn't organized so cool. Because Deequ provides not only a human-friendly hasSize way to define constraints, but also by directly calling a def addConstraint(constraint: Constraint): Check method. This method expects a Constraint Deequ object, which is not intended to be used directly by users, but by library developers. And it is exactly the mine case! Because Deequ allows to create Constraint from an Analyzer and Assertion (that is lamda expression). For example, the following code snippet create a Size constraint.
Implementation of fromAnalyzer(...): Constraint for the Size analyzer in Deequ:
def fromAnalyzer(size: Size, assertion: Long => Boolean, hint: Option[String]): Constraint = {
val constraint = AnalysisBasedConstraint[NumMatches, Double, Long](size,
assertion, Some(_.toLong), hint)
new NamedConstraint(constraint, s"SizeConstraint($size)")
}And because we already serialized to protobuf an expectations (that may be Double or Long for simplicity at the moment) and a sign we can easily transform it back to the lambda expression in the Scala code of the plugin:
private[ssinchenko] def parseSign[T: Numeric](reference: T, sign: proto.Check.ComparisonSign): T => Boolean = {
sign match {
case proto.Check.ComparisonSign.GET => (x: T) => implicitly[Numeric[T]].gteq(x, reference)
case proto.Check.ComparisonSign.GT => (x: T) => implicitly[Numeric[T]].gt(x, reference)
case proto.Check.ComparisonSign.EQ => (x: T) => implicitly[Numeric[T]].equiv(x, reference)
case proto.Check.ComparisonSign.LT => (x: T) => implicitly[Numeric[T]].lt(x, reference)
case proto.Check.ComparisonSign.LET => (x: T) => implicitly[Numeric[T]].lteq(x, reference)
case _ => throw new RuntimeException("Unknown comparison type!")
}
}When we have an assertion and an analyzer we can easily parse protobuf message to an actual Constraint object:
private[ssinchenko] def parseCheck(check: proto.Check): Check = {
val constraints = check.getConstraintsList.asScala.map { constraint: proto.Check.Constraint =>
{
val analyzer = parseAnalyzer(constraint.getAnalyzer)
val hint = if (constraint.hasHint) Some(constraint.getHint) else Option.empty
analyzer match {
case al: ApproxCountDistinct =>
Constraint.fromAnalyzer(
al,
assertion = parseSign(constraint.getDoubleExpectation, constraint.getSign),
hint = hint
)
....
case al: Uniqueness =>
Constraint.fromAnalyzer(
al,
assertion = parseSign(constraint.getDoubleExpectation, constraint.getSign),
hint = hint
)
case _ => throw new RuntimeException(s"Analyzer ${analyzer.getClass.getSimpleName} cannot be used in Check!")
}
}
}NOTE: While I added few tests to my scala-parsers, I did not cover all the implemented messages. At the moment I cannot guarantee that all the analyzers my tool is supporting are parsing in a right way.
The final object that is actually sent to the Spark-Connect via gRPC is a message that covers Deequ's VerificationSuite:
message VerificationSuite {
optional bytes data = 1;
repeated Check checks = 2;
repeated Analyzer required_analyzers = 3;
// Anomaly detection part
oneof repository {
FileSystemRepository file_system_repository = 4;
SparkTableRepository spark_table_repository = 5;
}
optional ResultKey result_key = 6;
repeated AnomalyDetection anomaly_detections = 7;
message FileSystemRepository {
string path = 1;
}
message SparkTableRepository {
string table_name = 1;
}
message ResultKey {
int64 dataset_date = 1;
map<string, string> tags = 2;
}
}The trickiest part is a optional byte data = 1;. These bytes represent a serialized protobuf message that is a Spark Connect Relation. In theory, it would be much better to import spark/connect into the protobuf code from the dependency, but for some reason the generated code is not compilable. This is already an asterisked question, my current hypothesis is that the problem is in the Maven Shade plugin used in Spark-Connect. So all Spark-Connect messages implement not com.google.protobuf.GeneratedMessageV3 but org.sparkproject.proto.GeneratedMessageV3. These classes should be identical to a human, but not to a Java compiler. So, since this is not Python with a duck typing, I just introduced a workaround: I put a serialized protobuf message as a field of another protobuf message that is also serialized.

By the end, I do not see a big problem there except the ugly code. This message should be deserialized only once for each Deequ run, so the overhead should be nothing compared to the cost of actual computations on data. But if you have an idea how to do it better, I will be happy to hear it!
Writing a plugin
As you may have noticed, I chose to write a plugin in Scala instead of Java. And there is a reason for that. While I still think Java is more reliable and readable for most use-cases, you're still better off using Scala if you need to do a lot of pattern matching. And pattern matching is exactly the case, because you need to transform protobuf messages into actual Deequ classes. Another reason is that Deequ itself is written in Scala, and calling some tricky Scala things from Java can be challenging.
The plugin itself is less than 30 lines of code, so let me put it here as is:
class DeequConnectPlugin extends RelationPlugin {
override def transform(relation: Any, planner: SparkConnectPlanner): Option[LogicalPlan] = {
if (relation.is(classOf[VerificationSuite])) {
val protoSuite = relation.unpack(classOf[VerificationSuite])
val spark = planner.sessionHolder.session
val protoPlan = org.apache.spark.connect.proto.Plan.parseFrom(protoSuite.getData.toByteArray)
val data = Dataset.ofRows(spark, planner.transformRelation(protoPlan.getRoot))
val result = DeequSuiteBuilder
.protoToVerificationSuite(
data,
protoSuite
)
.run()
val checkResults = VerificationResult.checkResultsAsJson(result)
val metricsResult = VerificationResult.successMetricsAsJson(result)
Option(
spark
.createDataFrame(
java.util.List.of(
Row(checkResults),
Row(metricsResult)
),
schema = StructType(Seq(StructField("results", StringType)))
)
.logicalPlan
)
} else {
Option.empty
}
}
}DeequSuiteBuilder there is just a helper object that contains all those parseSign, parseAnalyzer, etc. methods that I mentioned in the previous section.
Deequ VerificationResult object contains two main things:
- Results for checks;
- Computed metrics.
Because the only structure I can send back from a RelationPlugin is a Relation (or a LogicalPlan in other words) I made a decision to avoid overengineering and just put both results in a form of JSONs into a DataFrame with a single column and two rows:
val checkResults = VerificationResult.checkResultsAsJson(result)
val metricsResult = VerificationResult.successMetricsAsJson(result)
Option(
spark
.createDataFrame(
java.util.List.of(
Row(checkResults),
Row(metricsResult)
),
schema = StructType(Seq(StructField("results", StringType)))
)
.logicalPlan
)And that is it! Our plugin is ready to use!
Some nontrivial things
I still think the implementations of the plugin system in Spark 3.5 are a little broken. The problem here is again in the Maven Shade plugin. So, based on the RelationPlugin code, it expects com.google.protobuf.Any. But because the Spark compilation process itself replaces all com.google.protobuf patterns with org.sparkproject.protobuf, if you define your plugin using only com.google.protobuf it will fail at runtime. This problem is already fixed in Spark 4.0, where the RelationPlugin expects bytes instead of the protobuf message. But if you want to make your plugin work with the current 3.5 version of Spark, just add the following to your pom.xml (Apache Maven is assumed):
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<configuration>
<shadedArtifactAttached>false</shadedArtifactAttached>
<shadeTestJar>false</shadeTestJar>
<artifactSet>
<includes>
<include>com.google.protobuf:*</include>
</includes>
</artifactSet>
<relocations>
<relocation>
<pattern>com.google.protobuf</pattern>
<shadedPattern>org.sparkproject.connect.protobuf</shadedPattern>
<includes>
<include>com.google.protobuf.**</include>
</includes>
</relocation>
</relocations>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>google/protobuf/**</exclude>
</excludes>
</filter>
</filters>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>Another important thing to note is that you must use exactly the same version of the protoc compiler that is used to compile Apache Spark itself. You can check this in the Spark source code. For 3.5.1 these versions are:
<protobuf.version>3.23.4</protobuf.version> <!-- This version is taken from Apache Spark -->
<io.grpc.version>1.56.0</io.grpc.version> <!-- This version is taken from Apache Spark -->Testing it for PySpark Connect 3.5.1
Generating of the Python API from messages
Once you have a plugin and all the messages, the only thing left is to generate Python code from protobuf messages. I used a tool called buf to do this. The same tool is used in Apache Spark and in Spark-Connect Go projects. I can assume that this tool is some kind of industry standard for generating multi-language bindings from protobuf messages. My buf.gen.yaml looks like this:
version: v2
managed:
enabled: true
plugins:
# Python API
- remote: buf.build/grpc/python:v1.64.2
out: tsumugi_python/tsumugi/proto/
- remote: buf.build/protocolbuffers/python:v27.1
out: tsumugi_python/tsumugi/proto/
- remote: buf.build/protocolbuffers/pyi
out: tsumugi_python/tsumugi/proto/NOTE: Before you ask what "tsumugi" means, let me explain. Tsumugi or Tsumugi Shiraui is a character from the manga "Knights of Sidonia" that I'm currently reading. That's why I decided to name my project "tsumugi" and it contains "tsumugi-server" (plugin and messages) and "tsumugi_python" (PySpark Connect API). In the manga, Tsumugi is a chimera: a hybrid of human and Gauna. She combines the chaotic power of Gauna with a human intimacy and empathy. Like an original character of the manga "Knights of Sidonia", this project aims to make a hybrid of very powerful but hard to learn and use Deequ Scala library with the usability and simplicity of Spark Connect (PySpark Connect, Spark Connect Go, Spark Connect Rust, etc.).
![]()
A minimal working example of calling Deequ from PySaprk Connect with my plugin
The code-snippet below is reproducing the basic example from Deequ source code.
import json
import sys
from pathlib import Path
import pandas as pd
from pyspark.sql.connect.client import SparkConnectClient
from pyspark.sql.connect.dataframe import DataFrame
from pyspark.sql.connect.plan import LogicalPlan
from pyspark.sql.connect.proto import Relation
from pyspark.sql.connect.session import SparkSession
proj_root = Path(__file__).parent.parent.parent
print(proj_root)
sys.path.append(proj_root.absolute().__str__())
sys.path.append(proj_root.joinpath("tsumugi").joinpath("proto").absolute().__str__())
from tsumugi.proto import analyzers_pb2 as analyzers # noqa: E402
from tsumugi.proto import strategies_pb2 as strategies # noqa: E402, F401
from tsumugi.proto import suite_pb2 as base # noqa: E402
if __name__ == "__main__":
spark: SparkSession = SparkSession.builder.remote(
"sc://localhost:15002"
).getOrCreate()
# Data from https://github.com/awslabs/deequ/blob/master/src/main/scala/com/amazon/deequ/examples/BasicExample.scala
test_rows = [
{
"id": 1,
"productName": "Thingy A",
"description": "awesome thing.",
"priority": "high",
"numViews": 0,
},
...
]
data = spark.createDataFrame(pd.DataFrame.from_records(test_rows))
data.printSchema()
data.show()
suite = base.VerificationSuite()
suite.data = data._plan.to_proto(spark.client).SerializeToString()
check = suite.checks.add()
check.checkLevel = base.CheckLevel.Warning
check.description = "integrity checks"
# Add required analyzer
req_analyzer = suite.required_analyzers.add()
req_analyzer.size.CopyFrom(analyzers.Size())
# First constraint
ct = check.constraints.add()
ct.analyzer.size.CopyFrom(analyzers.Size())
ct.long_expectation = 5
ct.sign = base.Check.ComparisonSign.EQ
# Second constraint
ct = check.constraints.add()
ct.analyzer.completeness.CopyFrom(analyzers.Completeness(column="id"))
ct.double_expectation = 1.0
ct.sign = base.Check.ComparisonSign.EQ
assert suite.IsInitialized()
class DeequVerification(LogicalPlan):
def __init__(self, suite: base.VerificationSuite) -> None:
super().__init__(None)
self._suite = suite
def plan(self, session: SparkConnectClient) -> Relation:
plan = self._create_proto_relation()
plan.extension.Pack(self._suite)
return plan
tdf = DataFrame.withPlan(DeequVerification(suite=suite), spark)
results = tdf.toPandas()
checks = json.loads(results.loc[0, "results"])
metrics = json.loads(results.loc[1, "results"])
print(json.dumps(checks, indent=1))
print(json.dumps(metrics, indent=1))You can see that I'm calling a plugin directly by extending the LogicalPlan class with my own. It may look ugly, but it is exactly the way it should be used. And of course such ugliness can be easily hidden under the hood by providing another thin API layer on top of the code generated by protoc and LogicalPlan!
In a couple of days I can even re-implement the exact API of the existing python-deequ project, if anyone is really interested.
Running an example
At the moment Spark-Connect is not a part of the Apache Spark distribution that creates some complexity about how to run it.
NOTE: Based on the voting in a Apache Spark mailing list, it looks that Spark-Connect will become a part of Apache Spark distribution soon.
To simplify testing I created a simple bash-script that run the Spark-Connect Server with all the plugins and Jars:
./sbin/start-connect-server.sh \
--wait \
--verbose \
--jars tsumugi-server-1.0-SNAPSHOT.jar,protobuf-java-3.25.1.jar,deequ-2.0.7-spark-3.5.jar \
--conf spark.connect.extensions.relation.classes=org.apache.spark.sql.DeequConnectPlugin \
--packages org.apache.spark:spark-connect_2.12:3.5.1And of course we need to get the Apache Spark itself and download missing JARs (protobuf-java, deequ itself and, of course, my plugin):
wget "https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz" && \
tar -xvf spark-3.5.1-bin-hadoop3.tgz && \
cp run-connect.sh spark-3.5.1-bin-hadoop3/ && \
cd spark-3.5.1-bin-hadoop3/ && \
cp ../run-connect.sh ./ && \
wget "https://repo1.maven.org/maven2/com/amazon/deequ/deequ/2.0.7-spark-3.5/deequ-2.0.7-spark-3.5.jar" && \
wget "https://repo1.maven.org/maven2/com/google/protobuf/protobuf-java/3.25.1/protobuf-java-3.25.1.jar"The missing thing is just to copy a tsumugi-server JAR that is a result of mvn clean package -DskiptTests to the folder with a spark distribution and run sh run-connect.sh that starts the server.
Running a Python example will produce something like this:
[
{
"check_status": "Success",
"check_level": "Warning",
"constraint_status": "Success",
"check": "integrity checks",
"constraint_message": "",
"constraint": "SizeConstraint(Size(None))"
},
{
"check_status": "Success",
"check_level": "Warning",
"constraint_status": "Success",
"check": "integrity checks",
"constraint_message": "",
"constraint": "CompletenessConstraint(Completeness(id,None,Some(AnalyzerOptions(Ignore,NULL))))"
}
]
[
{
"entity": "Dataset",
"instance": "*",
"name": "Size",
"value": 5.0
},
{
"entity": "Column",
"instance": "id",
"name": "Completeness",
"value": 1.0
}
]Bonus
As you may have noticed, the same protobuf messages will work from any Spark-Connect implementation (Java, Scala, Go, Rust, C#). But what about Spark Classic? What if a developer needs to maintain both Classic and Connect? And I have good news. The same protobuf structures can be used to work from PySpark Classic! The only change is that instead of passing DataFrame as a serialized plan, you can pass it directly to DeequSuiteBuilder.protoToVerificationSuite(data: DataFrame, verificationSuite: proto.VerificationSuite): VerificationRunBuilder with Java-bridge!
spark: SparkSession = (
SparkSession.builder.master("local[1]")
.config(
"spark.jars",
proj_root.parent.joinpath("tsumugi-server")
.joinpath("target")
.joinpath("tsumugi-server-1.0-SNAPSHOT.jar")
.absolute()
.__str__(),
)
.getOrCreate()
)
# Data from https://github.com/awslabs/deequ/blob/master/src/main/scala/com/amazon/deequ/examples/BasicExample.scala
test_rows = [
...
]
data = spark.createDataFrame(pd.DataFrame.from_records(test_rows))
data.printSchema()
data.show()
suite = base.VerificationSuite()
check = suite.checks.add()
check.checkLevel = base.CheckLevel.Warning
check.description = "integrity checks"
# Add required analyzer
...
# First constraint
...
assert suite.IsInitialized()
deequ_JVM_builder = spark._jvm.com.ssinchenko.DeequSuiteBuilder
result = deequ_JVM_builder.protoToVerificationSuite(data._jdf, suite).run()
checks = json.loads(
spark._jvm.com.amazon.deequ.VerificationResult.checkResultsAsJson(result)
)
metrics = json.loads(
spark._jvm.com.amazon.deequ.VerificationResult.successMetricsAsJson(result)
)And we are getting the same result like for the Connect version! All that we need to change is how the proto-suite is passed!
You know, the more I work with Spark-Connect, the more I'm starting to love it!
References
Did anyone actually scroll until that place? :D
All the mentioned code is placed in the repository "tsumugi-spark". I placed all my code into the GitHub repository If you want to thank me for that post, you can star the repo!
Thanks for reading this! I hope it was not too boring!