PySpark column-level lineage
Introduction
In this post, I will show you how to use information from the spark plan to track data lineage at the column level. Let's say we have the following DataFrame object:
from pyspark.sql import SparkSession, functions as F
spark = SparkSession.builder.master("local[*]").getOrCreate()
dat = spark.read.csv("/home/sem/github/farsante/h2o-data-rust/J1_1e8_1e5_5.csv", header=True)
dat.printSchema()Result:
root
|-- id1: string (nullable = true)
|-- id2: string (nullable = true)
|-- id4: string (nullable = true)
|-- id5: string (nullable = true)
|-- v2: string (nullable = true)Let's create some transformations on top of our dat object:
dat_new = (
dat.withColumn("id1_renamed", F.col("id1"))
.withColumn("id1_and_id2", F.concat_ws("_", F.col("id1"), F.col("id2")))
.withColumn("num1", F.lit(1))
.withColumn("num2", F.lit(2))
.filter(F.rand() <= F.lit(0.5))
.select("id1_renamed", "id1_and_id2", "id1", "num1", "num2")
.withColumn("hash_id", F.hash("id1_and_id2"))
.join(dat.select("id1", "id4"), on=["id1"], how="left")
.withColumn("hash_of_two_ids", F.concat_ws("_", "id4", "hash_id"))
.groupBy("id1_renamed")
.agg(F.count_distinct("hash_of_two_ids").alias("cnt_ids"), F.sum(F.col("num1") + F.col("num2")).alias("sum_col"))
)Even with such a small transformation, it is not at all obvious which column is coming from where. Tracking transformations is the goal of Data Lineage. There are several types of data lineage:
- At the data source level, when we want to track all data sources in the process of our transformations;
- At the column level, when we want to track how which column was transformed during the process.
In this post I will focus on the second one, but the first one can be achieved in a similar way. But to implement it, we need to understand a little bit how Apache Spark works, how lazy computations work, and what the Directed Acyclic Graph of computations is.
A short introduction to spark computations model and Catalyst
You can get a deeper dive by reading an original paper about Spark SQL and Catalyst: Spark SQL: Relational Data Processing in Spark. I will just give a top-level overview.
When you apply a transformation, like withColumn("num1", F.lit(1)), Spark only adds a step to the computation graph, but does not add an actual column to the PySpark DataFrame you are working with. So at any moment, DataFrame is not a "real" data, but just a directed graph of computation steps. PySpark provides a way to get a string representation of the plan, to work with a plan as with a real graph data structure you need to use the Scala/Java API of Apache Spark. When you perform an action, like df.count() or df.write, Spark will get your computation graph and make an execution. This is a very simplified view, because in reality there are many different intermediate steps:
- Transforming the parsed logical plan into an analyzed logical plan by resolving sources and column references;
- Optimizing the logical plan by applying optimization rules (such as moving
filterexpressions to the beginning of the plan, or movingselectexpressions to the source column level); - Generate different versions of physical plans based on the same optimized logical plan;
- Apply cost-based selection of the best physical plan;
- perform code generation based on the selected physical plan;
- Execute the code.
For anyone who wants to better understand how spark works with plans and how optimizations can be applied, I highly recommend the book How query engines work by Andy Grow, creator of the Apache Arrow Datafusion.
Getting a string-representation of plan in PySpark
But for now, we just need the parsed logical plan, so let's make a simple Python function that returns it:
import contextlib
from pyspark.sql import DataFrame
def get_logical_plan(df: DataFrame) -> str:
with contextlib.redirect_stdout(StringIO()) as stdout:
df.explain(extended=True)
plan_lines = stdout.getvalue().split("\n")
start_line = plan_lines.index("== Analyzed Logical Plan ==") + 2
end_line = plan_lines.index("== Optimized Logical Plan ==")
return "\n".join(plan_lines[start_line:end_line])It may look overly complicated, but there is no other way to get a string representation of the analyzed logical plan from PySpark. df.explain returns nothing, instead it prints all plans (analyzed logical, optimized logical, physical) to standard output. That's why we need to use contextlib.redirect_stdout. You can check what the whole output of df.explain looks like. It is broken up by lines like == Analyzed Logical Plan == and similar. Also, the analyzed logical plan always starts from the schema of the DataFrame, so we need to add another line.
Let's see what the plan looks like for our dat_new DataFrame that we created:
get_logical_plan(dat_new) Aggregate [id1_renamed#2430], [id1_renamed#2430, count(distinct hash_of_two_ids#2491) AS cnt_ids#2508L, sum((num1#2445 + num2#2454)) AS sum_col#2510L]
+- Project [id1#1321, id1_renamed#2430, id1_and_id2#2437, num1#2445, num2#2454, hash_id#2469, id4#2480, concat_ws(_, id4#2480, cast(hash_id#2469 as string)) AS hash_of_two_ids#2491]
+- Project [id1#1321, id1_renamed#2430, id1_and_id2#2437, num1#2445, num2#2454, hash_id#2469, id4#2480]
+- Join LeftOuter, (id1#1321 = id1#2478)
:- Project [id1_renamed#2430, id1_and_id2#2437, id1#1321, num1#2445, num2#2454, hash(id1_and_id2#2437, 42) AS hash_id#2469]
: +- Project [id1_renamed#2430, id1_and_id2#2437, id1#1321, num1#2445, num2#2454]
: +- Filter (rand(-7677477572161899967) <= 0.5)
: +- Project [id1#1321, id2#1322, id4#1323, id5#1324, v2#1325, id1_renamed#2430, id1_and_id2#2437, num1#2445, 2 AS num2#2454]
: +- Project [id1#1321, id2#1322, id4#1323, id5#1324, v2#1325, id1_renamed#2430, id1_and_id2#2437, 1 AS num1#2445]
: +- Project [id1#1321, id2#1322, id4#1323, id5#1324, v2#1325, id1_renamed#2430, concat_ws(_, id1#1321, id2#1322) AS id1_and_id2#2437]
: +- Project [id1#1321, id2#1322, id4#1323, id5#1324, v2#1325, id1#1321 AS id1_renamed#2430]
: +- Relation [id1#1321,id2#1322,id4#1323,id5#1324,v2#1325] csv
+- Project [id1#2478, id4#2480]
+- Relation [id1#2478,id2#2479,id4#2480,id5#2481,v2#2482] csvAs you can see, the analyzed logical plan contains all calculation steps from the last one to the first one (Relation ... csv). An important thing is that PySpark adds unique IDs to each column, so the final names in the plan are not real column names, but something like name#unique_id. This will help us a lot when we will create our column lineage parser, because it simplifies all things: you do not need to think about collisions or renaming, because PySpark has already solved all these problems!
Parsing plan to get column-lineage
As you can see, there is a limited list of possible operations:
Relation: mapping of columns to files or tables;- Project~: any column operation, such as
withColumn,withColumnRenamed,select, etc; - Filter~: any filter operation;
- Join~: various types of join operations;
- Aggregate~: aggregate operations;
There are also some additional cases like Union, but the union operation makes things very complex, so let's decide to avoid it. Just because if a plan contains Union it is very hard to parse it, because a column can appear in any side of a union-like operation…
Defining an output data-structure and user API
First, we need to define what our column lineage will look like and what the data structure representing the lineage will be. By design, the data lineage is a directed acyclic graph (or tree). One of the simplest ways to represent a graph-like structure is simply to use a list of edges (called an adjacency list). Nodes of our graph will contain not only ids, but also some additional information, like the description of the computation step. Let's store the attributes in a dict-like structure. And the API should be very simple: just a function that takes a DataFrame object and a column name. For simplicity, it might also be good to store the list of all nodes in the graph. Let's define the structure and a function signature:
from dataclasses import dataclass
@dataclass
class ColumnLineageGraph:
"""Structure to represent columnar data lineage."""
nodes: list[int] # list of hash values that represent nodes
edges: list[list[int]] # list of edges in the form of list of pairs
node_attrs: dict[int, str] # labels of nodes (expressions)
def get_column_lineage(df: DataFrame, columns: str) -> ColumnLineageGraph:
raise NotImplementedError()Creating recursive parsing function
We will be using a lot of regular expressions and we need to import them first:
import reTransforming from graph-nodes to column names
It doesn't really matter that our logical plan is a list of strings. By design and idea, it is the tree structure, and the best way to traverse the tree is, of course, a recursion. Let's create an inner recursive function to traverse the plan:
def _node2column(node: str) -> str:
"""Inner function. Transform the node from plan to column name.
Like: col_11#1234L -> col_11.
"""
match_ = re.match(r"([\w\d]+)#[\w\d]+", node)
if match_:
return match_.groups()[0]We also need a way to get a node ID from the column name. To do this, let's add another simple function:
def _get_aliases(col: str, line: str) -> tuple[list[str], str]:
"""Inner function. Returns all the aliases from the expr and expr itself."""
alias_exp = _extract_alias_expressions(col, line)
# Regexp to extract columns: each column has a pattern like col_name#1234
return (re.findall(r"[\w\d]+#[\w\d]+", alias_exp), alias_exp)Parsing ALIAS expressions
One of the most complicated cases in a Spark plan is an alias. You may be faced with the following options:
- Literal expressions, like
1 AS col#1234; - Just an alias, like
col1#1234 AS col2#1235; - An alias to the expression, like
(col1#1234 + col2#1235) AS col3#1236.
And the last one can contain an unlimited number of nested expressions. It is almost impossible to parse such a case via regular expressions, looks like we need to balance parentheses, as in Leetcode easy task. I will use a counter based approach, where we have a counter of unbalanced parentheses and we reach the end of the expression when the counter is zero.
def _extract_alias_expressions(col: str, line: str) -> str:
"""Inner function. Extract expression before ... AS col from the line."""
num_close_parentheses = 0 # our counter
idx = line.index(f" AS {col}") # the end of the alias expression we need to parse
alias_expr = [] # buffer to store what we are parsing
if line[idx - 1] != ")":
"""It is possible that there is no expression.
It is the case when we just make a rename of the column. In the plan
it will look like `col#123 AS col#321`;
"""
for j in range(idx - 1, 0, -1):
alias_expr.append(line[j])
if line[j - 1] == "[":
break
if line[j - 1] == " ":
break
return "".join(alias_expr)[::-1]
"""In all other cases there will be `(` at the end of the expr before AS.
Our goal is to go symbol by symbol back until we balance all the parentheses.
"""
for i in range(idx - 1, 0, -1):
alias_expr.append(line[i])
if line[i] == ")":
# Add parenthesis
num_close_parentheses += 1
if line[i] == "(":
if num_close_parentheses == 1:
# Parentheses are balanced
break
# Remove parenthesis
num_close_parentheses -= 1
"""After balancing parentheses we need to parse leading expression.
It is always here because we checked single alias case separately."""
for j in range(i, 0, -1):
alias_expr.append(line[j])
if line[j - 1] == "[":
break
if line[j - 1] == " ":
break
return "".join(alias_expr[::-1])It may look like magic, so let's check how it works on examples from our real plan representation:
_extract_alias_expressions(
"id1_and_id2#2437",
"Project [id1#1321, id2#1322, id4#1323, id5#1324, v2#1325, id1_renamed#2430, concat_ws(_, id1#1321, id2#1322) AS id1_and_id2#2437]"
)And the result is:
'concat_ws((_, id1#1321, id2#1322)'Looks like it works! Finally some of the knowledge from the Leetcode tasks was put into practice!
Parsing aggregation-like expressions
In most cases we do not need additional columns from the row of the plan, except for one that we are working with. The only exception is aggregation: it might be good to store information about aggregation keys in our final node attributes. Let's add a simple function to do this:
def _add_aggr_or_not(expr: str, line: str) -> str:
"""If the expr is aggregation we should add agg keys to the beginning."""
# We are checking for aggregation pattern
match_ = re.match(r"^[\s\+\-:]*Aggregate\s\[([\w\d#,\s]+)\].*$", line)
if match_:
agg_expr = match_.groups()[0]
return (
"GroupBy: " + re.sub(r"([\w\d]+)#([\w\d]+)", r"\1", agg_expr) + f"\n{expr}"
)
# If not just return an original expr
return exprBuilding a final recursive parser
Now we have everything we need. So let's go through the logical plan line by line, adding nodes and attributes to our graph structure:
def _get_graph(lines: list[str], node: str):
nodes = []
edges = []
node_attrs = {}
for i, l in enumerate(lines): # noqa: E741
"""Iteration over lines of logical plan."""
# We should use hash of line + node as a key in the graph.
# It is not enough to use only hash of line because the same line
# may be related to multiple nodes!
# A good example is reading the CSV that is represented by one line!
h = hash(l + node)
# If the current node is not root we need to store hash of previous node.
prev_h = None if not nodes else nodes[-1]
if node not in l:
continue
if f"AS {node}" in l:
"""It is a hard case, when a node is an alias to some expression."""
aliases, expr = _get_aliases(node, l)
# For visualization we need to transform from nodes to columns
expr = re.sub(r"([\w\d]+)#([\w\d]+)", r"\1", expr)
# Append a new node
nodes.append(h)
# Append expr as an attribute of the node
node_attrs[h] = _add_aggr_or_not(f"{expr} AS {_node2column(node)}", l)
if len(aliases) == 1:
# It is the case of simple alis
# Like col1#123 AS col2#321
# In this case we just replace an old node by new one.
if prev_h:
edges.append([h, prev_h])
node = aliases[0]
else:
# It is a case of complex expression.
# Here we recursively go through all the nodes from expr.
if prev_h:
edges.append([h, prev_h])
for aa in aliases:
# Get graph from sub-column
sub_nodes, sub_edges, sub_attrs = _get_graph(lines[i:], aa)
# Add everything to the current graph
nodes.extend(sub_nodes)
edges.extend(sub_edges)
node_attrs = {**node_attrs, **sub_attrs}
# Add connection between top subnode and node
edges.append([sub_nodes[0], h])
return (nodes, edges, node_attrs)
else:
# Continue of the simple alias or expr case
# In the future that may be more cases, that is the reason of nested if instead of elif
if "Relation" in l:
nodes.append(h)
if prev_h:
edges.append([h, prev_h])
# It is a pattern, related to data-sources (like CSV)
match_ = re.match(r"[\s\+\-:]*Relation\s\[.*\]\s(\w+)", l)
if match_:
s_ = "Read from {}: {}"
# Add data-source as a node
node_attrs[h] = s_.format(match_.groups()[0], _node2column(node))
else:
# We need it to avoid empty graphs and related runtime exceptions
print(l)
node_attrs[h] = f"Relation to: {_node2column(node)}"
elif "Join" in l:
nodes.append(h)
if prev_h:
edges.append([h, prev_h])
match_ = re.match(r"[\s\+\-:]*Join\s(\w+),\s\((.*)\)", l)
if match_:
join_type = match_.groups()[0]
join_expr = match_.groups()[1]
join_expr_clr = re.sub(r"([\w\d]+)#([\w\d]+)", r"\1", join_expr)
node_attrs[h] = f"{join_type}: {join_expr_clr}"
else:
continue
if not nodes:
# Just the case of empty return. We need to avoid it.
# I'm not sure that line is reachable.
nodes.append(h)
node_attrs[h] = f"Select: {_node2column(node)}"
return (nodes, edges, node_attrs)All together
Now we are ready to put all the pieces together into a single function:
def get_column_lineage(df: DataFrame, column: str) -> ColumnLineageGraph:
"""Get data lineage on the level of the given column.
Currently Union operation is not supported! API is unstable, no guarantee
that custom spark operations or connectors won't break it!
:param df: DataFrame
:param column: column
:returns: Struct with nodes, edges and attributes
"""
lines = get_plan_from_df(df, PlanType.ANALYZED_LOGICAL_PLAN).split("\n")
# Top line should contain plan-id of our column. We need it.
# Regular pattern of node is column#12345L or [\w\d]+#[\w\d]+
match_ = re.match(r".*(" + column + r"#[\w\d]+).*", lines[0])
if match_:
node = match_.groups()[0]
else:
err = f"There is no column {column} in the final schema of DF!"
raise KeyError(err)
nodes, edges, attrs = _get_graph(lines, node)
return ColumnLineageGraph(nodes, edges, attrs)Testing and drawing our implementation
Let's see how our function works:
get_column_lineage(dat_new, "cnt_ids")Will produce the following:
ColumnLineageGraph(nodes=[-3047688324833821294, 8934572903754805890, -22248459158511064, -3092611391038289840, 1490298382268190732, -6431655222193019101, -1002279244933706460], edges=[[8934572903754805890, -3047688324833821294], [-22248459158511064, 8934572903754805890], [1490298382268190732, -3092611391038289840], [-6431655222193019101, 1490298382268190732], [-1002279244933706460, 1490298382268190732], [-3092611391038289840, 8934572903754805890]], node_attrs={-3047688324833821294: 'GroupBy: id1_renamed\ncount((distinct hash_of_two_ids) AS cnt_ids', 8934572903754805890: 'concat_ws((_, id4, cast(hash_id as string)) AS hash_of_two_ids', -22248459158511064: 'Read from csv: id4', -3092611391038289840: 'hash((id1_and_id2, 42) AS hash_id', 1490298382268190732: 'concat_ws((_, id1, id2) AS id1_and_id2', -6431655222193019101: 'Read from csv: id1', -1002279244933706460: 'Read from csv: id2'})Looks like it works, at least in our simple case.
Drawing the graph
To draw the graph as a tree, let's use the Python library NetworkX. And GraphViz as the drawing engine. You need to install the following packages to use it:
networkxpygraphvizmatplotlib
def plot_column_lineage_graph(
df: DataFrame,
column: str,
) -> "matplotlib.pyplot.Figure":
"""Plot the column lineage graph as matplotlib figure.
:param df: DataFrame
:param column: column
:returns: matplotlib.pyplot.Figure
"""
try:
import networkx as nx
from networkx.drawing.nx_agraph import graphviz_layout
except ModuleNotFoundError as e:
err = "NetworkX is not installed. Try `pip install networkx`. "
err += (
"You may use `get_column_lineage` instead, that doesn't require NetworkX."
)
raise ModuleNotFoundError(err) from e
try:
import matplotlib.pyplot as plt
except ModuleNotFoundError as e:
err = "You need matplotlib installed to draw the Graph"
raise ModuleNotFoundError(err) from e
import importlib
if not importlib.util.find_spec("pygraphviz"):
err = "You need to have pygraphviz installed to draw the Graph"
raise ModuleNotFoundError(err)
lineage = get_column_lineage(df, column)
g = nx.DiGraph()
g.add_nodes_from(lineage.nodes)
g.add_edges_from(lineage.edges)
pos = graphviz_layout(g, prog="twopi")
pos_attrs = {}
for node, coords in pos.items():
pos_attrs[node] = (coords[0], coords[1] + 10)
nx.draw(g, pos=pos)
nx.draw_networkx_labels(g, labels=lineage.node_attrs, pos=pos_attrs, clip_on=False)
return plt.gcf()If we run it, we get the following:
import matplotlib.pyplot as plt
col = "cnt_ids"
f = plot_column_lineage_graph(dat_new, col)
f.show()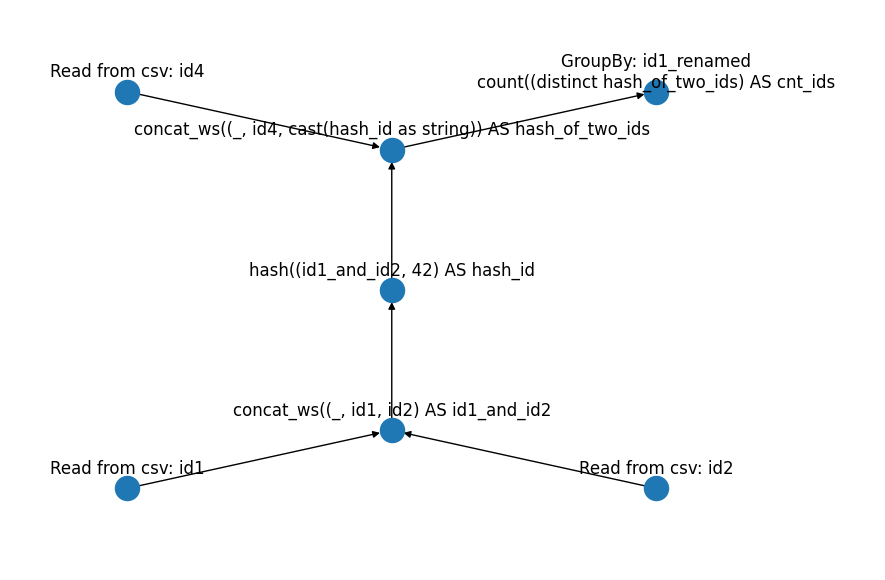
Looks exactly as what we need!
Afterwards
This functionality is mostly for educational purposes, to better understand how Spark Plan is organized. Another possible use case is if you need some simple inline Python code for this task. For real production data lineage on top of Spark, I recommend using a Spline Project!