Introduction: data governance in DataLakes
Unlike traditional OLTP or OLAP databases, the data lake and it's successor, the lakehouse, is not actually a database. The concept of the data lake, as I understand it, is that we have
- A distributed file system with relatively low storage costs and strong guarantees of fault tolerance;
- Files in this distributed FS, which can be anything: text, logs, bits, tables, etc;
- A query engine or framework that allows us to run SQL queries against these files;
- A metastore (like Hive-compatible), which is really just an OLTP system that contains a mapping of table names and metadata to file locations.
As a result, we have quite cheap cold storage that is very good for storing anything, and that can look like an OLAP system to the analysts working with it.
State of the art
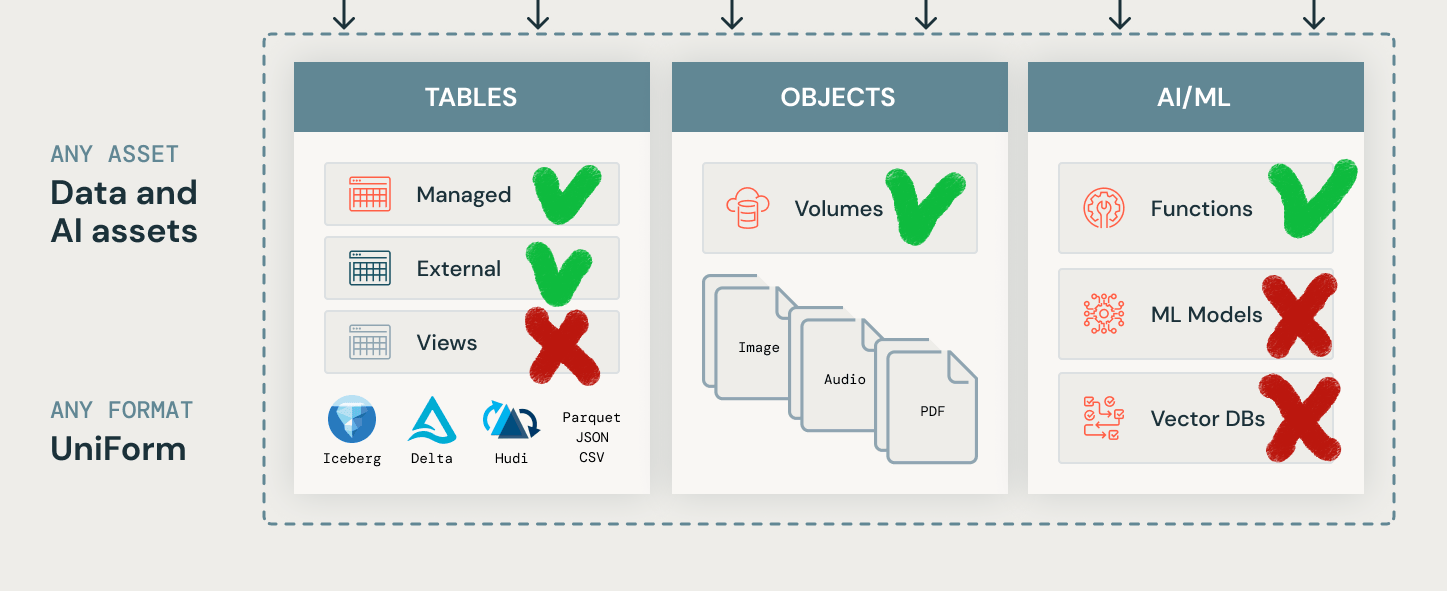
Unitycatalog is actually the first known solution to me that integrates both data and ML/AI assets into a single governance system. But this is only true for the proprietary version of Unity, which is only accessible in Databricks Runtimes. An open source version at the time of writing does not provide governance for ML models.
I love Databricks for their open source focus. But sometimes their marketing can be very aggressive and confusing. For example, saying that Unitycatalog is the industry's first unified governance solution sounds kind of weird when Apache Ranger has been with us for a decade.
Apache Ranger is a framework to enable, monitor and manage comprehensive data security across your data platform. It is an open-source authorization solution that provides access control and audit capabilities for big data platforms through centralized security administration.
Apache Ranger has the following goals:
- Centralized security administration to manage all security related tasks in a central UI or using REST APIs.
- Fine grained authorization to do a specific action and/or operation with Hadoop component/tool and managed through a central administration tool
- Standardize authorization method across all Hadoop components.
- Enhanced support for different authorization methods - Role based access control, attribute based access control etc.
- Centralize auditing of user access and administrative actions (security related) within all the components of Hadoop.
Of course, Ranger is very old, very complex, very hard to use, and as a person who has worked with it, it is very painful to work with. But I would say that Unitycatalog from Databricks is more like a modern alternative to Ranger, but not the "industry first".
Diving into the code
But let's put aside Databricks' aggressive marketing. Matei Zaharia open-sourced Unitycatalog in a live session at the recent Data+Ai Summit, and it was cool! So let's dive into the code and see what it can do for us compared to the state of the art.
Persistent storage
Let's start with one of the most important parts: persistent storage. Apache Ranger supports several backend RDBMSs for storing policies and accesses (MySQL, PostgreSQL, etc.). During configuration, you'll need to provide an existing database, and Ranger will create all its tables as part of the initialization process. Databricks Unitycatalog has both an advantage and a disadvantage. The upside is that Unity comes with an included (as a dependency) H2DB. The disadvantage is that Unity currently only supports H2DB. And this H2DB file is created in /etc/, so you cannot easily separate the policy server from the policy store. Migrating and backing up the DB is also difficult.
server/src/main/java/io/unitycatalog/server/persist/HibernateUtil.java:
configuration.setProperty("hibernate.connection.url", "jdbc:h2:file:./etc/db/h2db;DB_CLOSE_DELAY=-1");
configuration.setProperty("hibernate.hbm2ddl.auto", "update");
LOGGER.debug("Hibernate configuration set for production");I hope the persistent part will be changed soon and the current implementation with H2 is just for demonstration purposes. Because without the ability to choose a real RDBMS to store policies in, the solution is far from being ready for production, more like a playground from my point of view.
ML/AI Governance
The most promising and interesting part of Unitycatalog for me is the extension of governance to ML/AI objects. This is definitely a huge advantage over Apache Ranger, which does not offer anything like this. It is also a huge step forward because MLFlow, for example, has very limited authentication and permission management capabilities. There is no integration with something like Active Directory out of the box. And I was looking for Unitycatalog with the hope that it will finally be a unified solution that covers not only data in the data lake but also ML models/experiments. Unfortunately, the current OSS version does not offer anything related to ML…
I hope that Databricks will expose additional APIs related to ML/AI governance in future releases. Without that, it is hard to call the Unitycatalog truly unified.
Functions Governance
But the Functions API within the Unitycatalog looks like something really new and fresh. I don't know of anything competitive in the existing big data governance frameworks.
It provides two main functionalities:
- Register SQL function
- Register external function that can be in any language.
server/src/main/java/io/unitycatalog/server/model/CreateFunction.java
public enum RoutineBodyEnum {
SQL("SQL"),
EXTERNAL("EXTERNAL");
}Such a function may also have dependencies. A dependency is either a table or another function:
public class Dependency {
public static final String JSON_PROPERTY_TABLE = "table";
private TableDependency table;
public static final String JSON_PROPERTY_FUNCTION = "function";
private FunctionDependency function;
}The part of the documentation related to the Functions API is a little unclear, but from the code it looks like functions are bound to catalogs. But it is important that function names are unique, because names are keys, there is nothing like adding a hash or generating an internal ID. At least I have not found anything like that.
Anyway, the functionality looks really cool! I can imagine a lot of uses for it. For example, you could register something like audit functions, or delta-vacuum functions, or some SQL routines. Finally, a nice tool to unify access management for table functions!
A huge advantage of Unitycatalog over Apache Ranger!
Tables Governance
Table management is a functionality offered by almost all of Unitycatalog's competitors, including Apache Ranger. So let's see what the Databricks solution brings to the table.
Both external and managed tables are supported, so it is cool!
server/src/main/java/io/unitycatalog/server/model/TableType.java
public enum TableType {
MANAGED("MANAGED"),
EXTERNAL("EXTERNAL");
}In the marketing promo, Databricks claims that Unitycatalog is a unified tool that can be used with more than just delta tables. But in fact it cannot. This is because you cannot create an external table and map it to existing data in Iceberg/Hudi formats in your datalake:
server/src/main/java/io/unitycatalog/server/model/DataSourceFormat.java
public enum DataSourceFormat {
DELTA("DELTA"),
CSV("CSV"),
JSON("JSON"),
AVRO("AVRO"),
PARQUET("PARQUET"),
ORC("ORC"),
TEXT("TEXT");
}So, at the moment only Delta is supported. Apache Iceberg or Apache Hudi are supported only by extending metadata to delta-compatible one. It may be achieve via Apache XTable (incubating) or via Delta UniForm, of course. But still disappointing a little. For the comparison, Apache Ranger works with a Hive Metastore where you can register any of Delta, Iceberg and Hudi.
What really puzzles me is why Uniticatalog does not have a separate field for partitioning information in io.uniticatalog.server.model.TableInfo. Maybe for a DWH-like workload, hive-style partitioning is kind of outdated these days. But in my experience of a data engineer working in ML team, for batch ML-like/MLOps processing, old-school functional data engineering is still a perfect fit. I'm disappointed that Unitycatalog does not support information about partitioning. Especially considering that it was announced for ML/AI governance.
I'm actually wondering now, does Unicatalog actually support hive-style partitioning?
Volumes Governance
Technically, Apache Ranger supports the management of unstructured data in the same way as tables. This can be achieved in Ranger by registering a policy on a path. Unitycatalog provides a more user friendly API in my opinion. This API is called "Volumes". The support of both managed and external volumes is claimed:
server/src/main/java/io/unitycatalog/server/model/VolumeType.java
public enum VolumeType {
MANAGED("MANAGED"),
EXTERNAL("EXTERNAL");
}But at the moment you can actually creates only external one…
server/src/main/java/io/unitycatalog/server/persist/VolumeRepository.java
if (VolumeType.MANAGED.equals(createVolumeRequest.getVolumeType())) {
throw new BaseException(ErrorCode.INVALID_ARGUMENT, "Managed volume creation is not supported");
}Volumes are defined by path or storage_location. Also Unitycatalog generates unique IDs for each volume, so it looks like that names may be not unique:
volumeInfo.setVolumeId(UUID.randomUUID().toString());What is missing at the moment?
One of the most important part of any governance system for me is an audit capabilities. For example, Apache Ranger provides an audit APIs that allows you to check who accessed what. I did not find anything like this in the Unitycatalog at the moment. I hope such an API will be provided soon.
Conclusion
At the time of this writing, Unitycatalog looks more like a proof of concept or MVP than a production-ready solution. There are no audit capabilities, no external RDBMS persistent storage support. All ML/AI governance features are currently missing. Big questions were raised about the lack of support for hive-style partitioning.
Nevertheless, it looks like a big step forward. I have been waiting for a modern alternative to Apache Ranger for a long time. And the mentioned extension of governance to AI/ML looks very promising.
I'm looking forward to future releases of Unity! Thanks to Databricks for following the open source path!