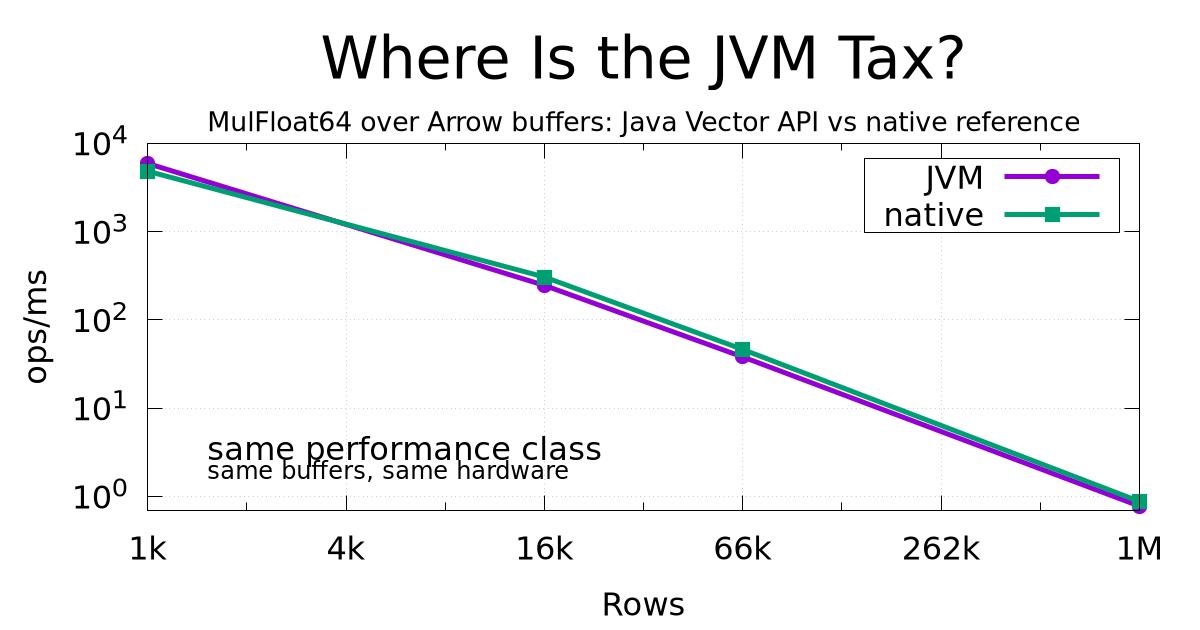
Same buffers, same instructions, same hardware. Where Is the JVM Tax?
A small Java + Apache Arrow + Vector API benchmark against native library code. Same buffers, same hardware, same performance class — so where exactly is the alleged JVM tax?
A small Java + Apache Arrow + Vector API benchmark against native library code. Same buffers, same hardware, same performance class — so where exactly is the alleged JVM tax?
Preface I would like to express my gratitude to Matthew Powers for testing my project and providing feedback, and to Steve Russo for offering a valuable review of my code and drawing my attention to avoiding the use of unwrap. Prior to his review, some parts of the code looked like this: let distr_k = Uniform::<i64>::try_from(1..=k).unwrap(); let distr_nk = Uniform::<i64>::try_from(1..=(n / k)).unwrap(); let distr_5 = Uniform::<i64>::try_from(1..=5).unwrap(); let distr_15 = Uniform::<i64>::try_from(1..=15).unwrap(); let distr_float = Uniform::<f64>::try_from(0.0..=100.0).unwrap(); let distr_nas = Uniform::<i64>::try_from(0..=100).unwrap(); ...